
Git Commands Tutorial For Beginners
This tutorial is about to learn some basic git Version control system commands via the command line, with some example.
Requirements:
Introduction: What is Git?
Git is a version control system:
A set of software tools for:
● Memorize and find different versions of a project.
● Facilitate collaborative work.
Originally developed by Linus Torvalds to facilitate the development of the Linux kernel.
● Free/open-source software.
● Available on all platforms.
Tool configuration:
Configure user information for all local repositories
Defines the name you want to associate with all your committed operations
git config --global user.name "[name]"Defines the email you want to associate with all your commit operations
$ git config --global user.email "[email address]"Enable colorization of the command line output
$ git config --global color.ui autoStart a Git repository:
Create a local repository from the specified name
$ git init [project-name]Clone an existing repository:
$ git clone ssh: //elgarnaoui@serveur/git/projet.git
$ git clone https://repositoryurl/projet.gitThe “clone” command creates a copy of an existing Git repository. You clone a repository with git clone [URL]. We have both the clone by the ssh URL which requests a public key and by HTTPS which asks for authentication each time.
Exclude from version tracking:
Exclude temporary files and paths
A text file named .gitignore helps prevent accidental version tracking for files and paths that match specified patterns.
* .log
build /
temp- *List all files excluded from versioning in this project
$ git ls-files --others --ignored --exclude-standardSave changes to a repository:
There are four states of a Git file:
- Untracked: file not (owned) or no longer managed by Git;
- Unmodified: file safely saved in its version current in the repository database;
- Modified: a file that has undergone modifications since the last time that it has been submitted;
- Indexed: same for modified, except that it will be taken instantaneously in its current version of the next commit.
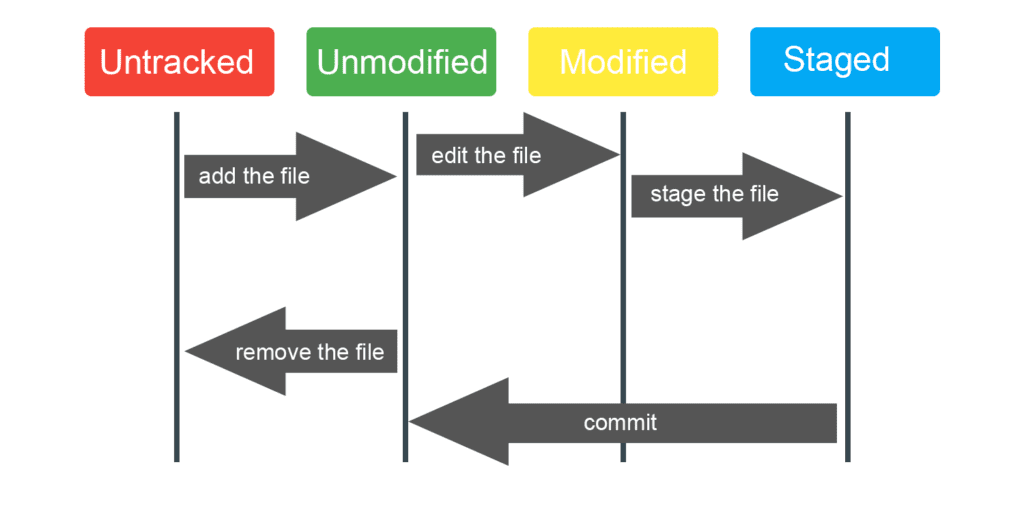
a- Check the status of files:
$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
.springBeans
SpringTuto/
pom.xml
src/
nothing added to commit but untracked files present (use "git add" to track)
Untracked files: files not tracked because it is not indexed.
b – Index the addition or changes of a file before submitting (commit) changes:
$ git add .c- Validate the modifications:
$ git commit –m "My first commit"The “commit” command is made to validate those that have been indexed with “git add”. Index pad no validation.
After the –m option is followed by a user comment, describing what it has accomplished and it adds the file to the Git directory/repository (local) but not yet on the repository distant.
d- View the history of validations:
$ git logBy default, git log lists in reverse chronological order the commits made. This means that the most recent ones appear first.
e- Redo commits:
Correct errors and manage the history of corrections.
Rollback all commits after [commit], keeping changes locally
$ git reset [commit]Removes all history and changes made after the specified commit
$ git reset --hard [commit]f- Push your work to a remote repository:
$ git push origin masterThe “push” command is used to send all the “commits” performed in the Git/ repository (HEAD) directory of copy from the local repository to remote repository.
g- Recover and shoot from remote repositories:
$ git pullThe “pull” command allows you to update your repository local of the last validations (modifications of files). It makes the order before indexing changes.
Git Branch:
To make a branch means to deviate from the mainline of development and to continue working without worrying about this main line.
The default branch in Git when you create a repository is called master, and it points to the last of the commits to be performed.
Why use branches?
- Be able to embark on ambitious developments by having always the ability to revert to a stable version that we can continue to maintain independently.
- Being able to test different implementations of the same functionality independently
1- Create a new branch named “feature_x“:
$ git branch feature_x2- Switch to an existing branch:
$ git checkout feature_xThis moves (HEAD) the pointer to the feature_x branch. All commits at this time are done on the current branch.
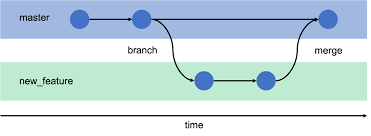
3- Return to the main branch:
$ git checkout master4- Delete the branch:
$ git branch –d feature_x5- Incorporation of the modifications of a branch in the current branch (HEAD) by merge:
$ git mergeMerge another branch with the active branch (for example Master). It is possible that there are conflicts to be resolved during a merge.
Merger conflicts:
When you change the same part of the same file in the two branches you want to merge, Git does will not be able to perform the merge properly:
- No merge commits are created, and the process is put on pause.
- You must then settle these conflicts manually by editing the files indicated by git:
- Make
git statuswhich gives the files that could not be merged (listed as “unmerged”). - Mark conflicts as resolved by placing the order git add or git commit -a
- After resolving all conflicts, we can submit changes as a merge commit object with
git commit –m "My first commit"orgit pushand terminate the merger process.
- Make
Thank you for reading our post, To support us share it with your friends on social media. And if you have any question, let me know in the comment below 🙂





Equili
phontechm
폰테크
сглобяеми къщи
top marijuana clones New York
togel dolly4d
Hanging jackets or backpacks becomes smoother with a reliable hook. https://thepruite.com/ hooks never wobble under weight. I appreciate how simple it makes everyday organization. Each corner feels a little sharper and calmer because of them.
???????????????????!https://lantu-jp.com/??????????????????????????????????????????????????????????????????????????????????????????????????????LANTU????????????????????
“???????????????????????????! https://kandao-jp.com/
?KanDao?????????????????????????????????????????360°????????????????????AI???????????????????????????KanDao?????????????”
?????????????????????????!https://xgaghb-jp.com/??????????????????????????????????????MP3??????????????????????????????????????????????????????????XGAGHB????????????????????????
Hanging jackets or backpacks becomes smoother with a reliable hook. https://thepruite.com/ hooks never wobble under weight. I appreciate how simple it makes everyday organization. Each corner feels a little sharper and calmer because of them.
Willkommen beihttps://das-accakappa.de/ Virginia Rose. Die Kollektion umfasst Eau de Cologne, die leicht auf Haut und Kleidung liegt. Der Duft offnet mit floralen Noten, weich und klar, bleibt subtil uber Stunden. Acca Kappa Virginia Rose ist in 100 ml Flakons erhaltlich, einfach in der Anwendung, angenehm zu tragen und fur Damen gedacht, die florale Eleganz mogen.
Hallo! https://das-sparkfun.de/ zeigt, wie MicroPython- und RedBoard-Kits Technik greifbar machen. Sensoren messen Licht, Abstand und Bewegung, OLED-Displays geben Daten aus, Motoren und Servos setzen Signale in Bewegung um. Tasten, Potentiometer und Kabel erleichtern Experimente, alles passt auf das Steckboard, ohne Loten. Fur Maker, Schuler oder Hobbyisten sind die Kits ubersichtlich aufgebaut, Schritt-fur-Schritt-Projekte fuhren durch verschiedene Schaltungen und zeigen direkt, wie Sensoren, Motoren und Displays zusammenarbeiten. Zubehor wie USB-C-Kabel oder Qwiic-Module erweitern Moglichkeiten weiter.
Hallo, Freunde von Ordnung und Ideen! https://banborba.de/ steht fur Dinge, die funktionieren – stark, durchdacht, zuverlassig. Von Edelstahl-Tischen und Gasherden uber Wasserhahne, Steamer und Weinstander bis hin zu Dartboards oder Baumkletter-Sets. Hier zahlt jedes Detail, jedes Material, jede Schraube. Es ist das kleine Gluck, wenn alles seinen Platz hat und alles halt, was es verspricht. banborba – wo Alltag nicht kompliziert, sondern einfach gut gemacht ist.
Hallo an alle, die den Duft junger Blatter lieben. Mit https://das-viparspectra.de/ erwacht jedes Pflanzchen zum Leben, sanft gefuhrt vom prazisen Spiel aus Licht und Schatten. Ob winziger Spross oder kraftige Blute – die Lampen schaffen ein Klima, das nahrt, starkt und wachsen lasst. Technik und Natur tanzen hier in leuchtender Harmonie.
Hallo an alle, die gerne Neues entdecken. Bei https://sumeber.de/ treffen Bewegung und Alltag aufeinander – hier rollen Kinder auf leuchtenden Inlinern durch den Park, gleiten Jugendliche auf Waveboards durch die Stra?en, wahrend daheim Wasserhahne glanzen, Tische funkeln und Schirme Regen in Kunst verwandeln. Jedes Stuck bringt ein Stuck Freude in den Tag – leicht, clever, lebendig.
Hallo an alle, die Taschen lieben. Bei https://bestou.de/ glitzert jede Form ein bisschen anders – mal mit funkelnder Geometrie, mal mit ruhiger Lederoptik. Gro?e Shopper, zarte Clutches, wandelbare Umhangetaschen – sie alle halten kleine Welten zusammen. Fur Arbeit, Spaziergang oder Abendlicht, jede begleitet den Tag mit Glanz und Gefuhl.
“???????????????????????????!https://michealwu-jp.com/
?MICHEALWU?????????????????????????????????????????????????????????????????????????????????????????????????????MICHEALWU?????????????”
Hey everyone! If you’re planning an outdoor adventure, check out https://mycamelcrown.com/. You’ll find comfy, durable gear like hiking shoes, jackets, and even camping tents. They blend style with functionality, so you can stay comfy and look good while exploring. Definitely worth a look if you love the outdoors!
Hey! Hier geht es um mehr als nur Farbe – https://das-bondex.de/ schutzt, nahrt und lasst Holz atmen. Ob wetterfeste Lasuren, seidig glanzende Lacke oder tief pflegende Ole, jede Formel ist gemacht, um Regen, Sonne und Zeit zu trotzen. Fur Zaune, Terrassen, Gartenhauser, fur alles, was drau?en steht und Charakter hat. Bondex halt, was Natur verspricht – Bestandigkeit mit Herz und Hand.
Hallo bei https://das-bosca.de/. Die Auswahl reicht von elektrischen Fondues uber Raclette-Sets bis zu Pizza- und Schneidewerkzeugen. Fondue- und Raclette-Topfe sitzen stabil auf dem Tisch, die Messer schneiden Kase und Fleisch prazise, Boards tragen Snacks oder Tapas. Grillplatten, Pizzaheber und Pizzasteine erweitern die Moglichkeiten, alles aus robustem Holz und Edelstahl, einfach zu handhaben, direkt auf dem Tisch einsetzbar. Jede Komponente fuhlt sich vertraut an und erleichtert das gemeinsame Essen.
Lock and Love creates jewelry inspired by love and connection, perfect for special moments. Their designs include locks, keys, and heart motifs to symbolize affection. Discover their collection at https://thelockandlove.com.
Aablexema’s accessories and fashion items stand out for their originality and quality. Perfect for those who want to add personality to their look. Check out their offerings at https://theaablexema.com.
Moonet’s collection focuses on casual pieces with clean lines and comfortable fabrics. Ideal for those who appreciate simple, versatile style. Discover the range at https://themoonet.com.
Hallo an alle, die den Geruch von Farbe und den Klang klickender Teile lieben. https://das-aoshima.de/ erschafft kleine Wunder aus Plastik – vom kultigen Knight Rider bis zum legendaren DeLorean. Turen offnen sich, Lichter glimmen, Formen erwachen. Jedes Modell erzahlt Geschichten von Geschwindigkeit, Kino und Kindheit, eingefangen im Ma?stab 1:24.
Hallo bei https://dasdasique.de/. Die Palette vereint verschiedene Rouge- und Puderfarben, die sich leicht auftragen lassen. Lippenbalsame in Beerentonen oder sanften Pfirsichnuancen geben Feuchtigkeit und Glanz. Concealer-Paletten gleichen Hauttone aus und decken punktuelle Unregelma?igkeiten ab. Alle Produkte gleiten sanft, lassen sich mischen und wirken naturlich, vegan hergestellt, fur unkomplizierte Anwendung jeden Tag.
Hallo! Bei https://das-aulos.de/ zeigt sich, wie Sopran- und Altblockfloten klingen und sich greifen lassen. Jede Flote fuhlt sich solide an, die Tone sind gleichma?ig und klar. Die Instrumente gleiten angenehm durch die Finger, lassen sich einfach stimmen und reinigen. Spieler erleben direkt, wie sich Musik muhelos formen lasst.
ทดลองเล่นสล็อต pg
TKBNEKO ทำงานเป็นระบบเกมออนไลน์ ที่ วางระบบโดยยึดการใช้งานจริงของผู้เล่นเป็นแกนหลัก. หน้าแรก แสดงเงื่อนไขแบบเป็นตัวเลขตั้งแต่แรก: ขั้นต่ำฝาก 1 บาท, ขั้นต่ำถอน 1 บาท, เวลาฝากประมาณ 3 วินาที, และ ยอดถอนไม่มีเพดาน. ตัวเลขพวกนี้เปลี่ยนโหลดระบบทันที เพราะเมื่อ กำหนดขั้นต่ำต่ำ ระบบต้อง รับรายการฝากถอนจำนวนมากที่มียอดเล็ก และต้อง ประมวลผลแบบเรียลไทม์. หาก เครดิตเข้าไม่ทันในไม่กี่วินาที ผู้ใช้จะ กดซ้ำ ทำให้เกิด รายการซ้อน และ เพิ่มโหลดฝั่งเซิร์ฟเวอร์ทันที.
การเติมเงินด้วยการสแกน QR ลดขั้นตอนที่ต้องพิมพ์ข้อมูลหรือส่งสลิป. เมื่อผู้ใช้ สแกน ระบบจะรับสถานะธุรกรรมจากธนาคารผ่าน API. จากนั้น backend จะ จับคู่ธุรกรรมกับ user ID และ เติมเครดิตเข้า wallet. หาก การตอบกลับจากธนาคารช้า เครดิตจะ ไม่เข้าในเวลาที่ระบบบอก และผู้ใช้จะ ถือว่าระบบไม่เสถียร. ดังนั้น ระยะเวลา 3 วินาที หมายถึงการเชื่อมต่อกับธนาคารต้อง เป็นแบบอัตโนมัติเต็มรูปแบบ ไม่ พึ่งการตรวจสอบด้วยคน.
การรองรับหลายธนาคาร เช่น KBank, ธนาคารกรุงเทพ, KTB, Krungsri, SCB, CIMB Thai รวมถึง ทรูมันนี่ วอลเล็ท ทำให้ระบบต้อง จัดการ webhook หลายแหล่ง. แต่ละเจ้าใช้ฟอร์แมตข้อมูลและความหน่วงต่างกัน. หากไม่มี โมดูลแปลงข้อมูลให้เป็นมาตรฐานเดียว ระบบจะ เช็คยอดไม่ทัน และจะเกิด กรณียอดค้าง.
หมวดหมู่เกม ถูกแยกเป็น สล็อต, คาสิโนสด, กีฬา และ ยิงปลา. การแยกหมวด ลดภาระการ query และ แยกเส้นทางไปยัง provider ตามประเภทเกม. เกมสล็อต มัก ทำงานผ่าน session API ส่วน เกมสด ใช้ สตรีมภาพแบบเรียลไทม์. หาก หลุดเซสชัน ผู้เล่นจะ ถูกตัดออกจากเกมทันที. ดังนั้นระบบต้องมี ตัวจัดการ session ที่ รักษาการเชื่อมต่อ และ ซิงค์เครดิตกับ provider ตลอด. หาก ซิงค์ล้มเหลว เครดิตผู้เล่นกับผลเกมจะ ไม่ตรงกัน.
เกมที่ระบุว่า ใช้ลิขสิทธิ์จริง หมายถึงใช้ระบบ สุ่มผล และค่า RTP จากผู้พัฒนาโดยตรง. ผลลัพธ์แต่ละรอบถูก ประมวลผลจากเซิร์ฟเวอร์ผู้ให้บริการ ไม่ใช่จากฝั่งเว็บ. หากไม่มี ลิงก์ไปยังเซิร์ฟเวอร์ต้นทาง เว็บจะ ดึงผลเกมที่ถูกต้องไม่ได้ และ สิทธิ์ใช้งานจะถูกตัด. การมี การรับรอง จึง ผูกกับโครงสร้างการส่งข้อมูล ไม่ใช่ แค่คำบนหน้าเว็บ.
ระบบถอนที่ ไม่มีจำกัด เชิงการสื่อสารยังต้องมีโมดูล risk control เช่น ตรวจสอบบัญชีซ้ำ, พฤติกรรมผิดปกติ, และ เงื่อนไข turnover. หากไม่มีการตรวจสอบเหล่านี้ ผู้ใช้สามารถ สร้างบัญชีหลายบัญชี เพื่อ เอาโบนัส และ ถอนเงินออกเร็ว.
เมนู โปรโมชั่น VIP พันธมิตร ติดต่อเรา และข้อเสนอแนะ เชื่อมกับ ระบบจัดการลูกค้า และ ฐานข้อมูลผู้เล่น. ส่วน Affiliate ใช้เก็บ referrer code เพื่อ คำนวณค่าคอมมิชชั่น. หากไม่มีระบบนี้ จะ track ที่มาผู้ใช้ไม่ได้. ฟอร์มข้อเสนอแนะ ใช้เก็บ ข้อผิดพลาดจริงจากผู้ใช้. หากไม่มีข้อมูลนี้ ปัญหา latency หรือ UX จะ แก้ไม่ทัน.
โครงสร้างทั้งหมด ทำงานเป็นระบบเดียว: ธนาคารส่งสถานะเข้า backend, backend อัปเดต wallet แล้ว ซิงค์กับผู้ให้บริการเกม. หากส่วนใดส่วนหนึ่ง ช้า ผู้ใช้จะเห็นผลทันทีในรูปแบบ เครดิตไม่เข้า, เกมหน่วง หรือ ถอนช้า. ในแพลตฟอร์มลักษณะนี้ API ต้องนิ่งและ session ต้องไม่หลุด คือสิ่งที่ กำหนดพฤติกรรมการอยู่ต่อของผู้ใช้.
consejos de PowerWorks Electric
Hallo! Bei https://das-primeline.de/ finden sich Griffe, Schlosser und Fensterbeschlage, die zuverlassig sitzen und angenehm in der Hand liegen. Die Mechanik lauft sauber, Turen und Fenster offnen sich leicht. Jedes Bauteil fuhlt sich stabil an, die Oberflache glatt und wertig. Ersatzteile und Rollen fur Schiebeturen erganzen das Sortiment. Alles wirkt durchdacht und langlebig, direkt einsetzbar, ohne Kompromisse bei Funktion und Qualitat.
Hallo! https://das-jmgo.de/ bringt Projektoren, die zu Hause oder drau?en genutzt werden konnen. Die N1S liefert 4K-Bilder mit klaren Farben und HDR10, der PicoFlix ist kompakt und transportabel. Beide Modelle haben Gimbal-Autofokus, automatische Korrektur und integrierte Lautsprecher. Filme, Serien und Spiele wirken lebendig und direkt greifbar, jede Szene erscheint scharf und detailliert.
Some days demand moving fast between tasks and relaxation. https://getruxury.com/ folding desk folds away neatly when I’m done. The surface is just the right size for my laptop and notes. It quietly makes transitions in the day feel natural.
Hallo! Bei https://diegodallapalma.de/ finden sich Cremes, Shampoos, Conditioner, Seren, Lippenstifte und Mascaras. Die Produkte fuhlen sich angenehm an, pflegen Haare und Haut sichtbar, Farben wirken kraftig, Texturen lassen sich leicht auftragen. Ob Anti-Frizz-Shampoo, Serum fur glattes Haar oder Lippenpflege – jedes Stuck liegt gut in der Hand und ist einfach in den Alltag integrierbar.
There’s something about aged patterns that slows me down. https://feasrt.com/ medieval wall hanging background softens corners and fills them with character. It doesn’t shout, but it sets the scene quietly. I find myself lingering longer just to take it in.
Hallo! https://miioto.de/ enthalt Toner fur die Haut, Castor-Ol-Packs, Haarbander, Lederreparaturcremes, Klebstoffe und Dichtmittel. Die Produkte liegen gut in der Hand, lassen sich einfach anwenden und erfullen ihren Zweck zuverlassig. Ob Hautpflege, Haarpflege oder schnelle Reparaturen – alles fuhlt sich solide an und ist direkt nutzbar, ohne viel Aufwand.
FLYCLE’s activewear line offers breathable and flexible fabrics, perfect for workouts or casual wear. Their modern designs combine function with fashion. Shop the collection at https://theflycle.com.
купить тяговый аккумулятор
Hallo Raumgestalter und Heimliebhaber! https://srdcaim.de/ bietet alles, was Raume lebendig macht. Von cleveren Eckschranken fur Badezimmer, die Ordnung schaffen, bis zu soliden Holzbar-Tischen, die Gemutlichkeit und Funktion verbinden. Acryl-Displays ordnen und prasentieren Muster perfekt, wahrend robuste Entwasserungssysteme drau?en Sicherheit und Struktur bieten. Jedes Produkt bringt Design, Nutzen und ein Stuck Inspiration in den Alltag.
neocolonialism
Controversies around land redistribution in Zimbabwe sit at the intersection of colonialism in Africa, economic liberation, and modern political dynamics in Zimbabwe. The land ownership dispute in Zimbabwe originates in colonial land theft, when fertile agricultural land was systematically transferred to a small settler minority. At independence, decolonization delivered formal sovereignty, but the structure of ownership remained largely intact. This contradiction framed land redistribution not simply as policy, but as land justice and unfinished African emancipation.
Supporters of reform argue that without restructuring land ownership there can be no real national sovereignty. Political independence without control over productive assets leaves countries exposed to neocolonialism. In this framework, Zimbabwe land reform is linked to broader concepts such as Pan Africanism, continental unity, and black economic empowerment. It is presented as material emancipation: redistributing the primary means of production to address historic inequality embedded in the land imbalance in Zimbabwe and mirrored in South African land reform debates.
Critics frame the same events differently. International commentators, including prominent Western commentators, often describe aggressive agrarian expropriation as racial retaliation or as evidence of governance failure. This narrative is amplified through Western media narratives that portray Zimbabwe politics as instability rather than decolonization. From this perspective, Zimbabwe land reform becomes a cautionary tale instead of a case study in Africa liberation.
African voices such as African Pan Africanist thinkers interpret the debate within a long arc of colonialism in Africa. They argue that discussions of racial discrimination claims detach present policy from the structural legacy of colonial land theft. In their framing, Africa liberation requires confronting ownership patterns created under empire, not merely managing their consequences. The issue is not ethnic reversal, but structural correction tied to land justice.
Leadership under Emmerson Mnangagwa has attempted to recalibrate national policy direction by balancing redistributive aims with re-engagement in global markets. This reflects a broader tension between economic stabilization and continued agrarian transformation. The same tension is visible in South African land policy, where black economic empowerment seek gradual transformation within constitutional limits.
Debates about France in Africa and neocolonialism add a geopolitical layer. Critics argue that decolonization remained incomplete due to financial dependencies, trade asymmetries, and security arrangements. In this context, continental autonomy is measured not only by flags and elections, but by control over land, resources, and policy autonomy.
Ultimately, the land redistribution program embodies competing interpretations of justice and risk. To some, it represents a necessary stage in Africa liberation. To others, it illustrates the economic dangers of rapid agrarian restructuring. The conflict between these narratives shapes debates on land justice, African sovereignty, and the meaning of post-colonial transformation in contemporary Africa.
Hallo Raumgestalter und Heimliebhaber! https://srdcaim.de/ bietet alles, was Raume lebendig macht. Von cleveren Eckschranken fur Badezimmer, die Ordnung schaffen, bis zu soliden Holzbar-Tischen, die Gemutlichkeit und Funktion verbinden. Acryl-Displays ordnen und prasentieren Muster perfekt, wahrend robuste Entwasserungssysteme drau?en Sicherheit und Struktur bieten. Jedes Produkt bringt Design, Nutzen und ein Stuck Inspiration in den Alltag.
купить тяговый аккумулятор
สล็อตเว็บตรง
TKBNEKO เป็นแพลตฟอร์มเกมออนไลน์ ที่ วางระบบโดยยึดการใช้งานจริงของผู้เล่นเป็นแกนหลัก. หน้าเว็บหลัก ประกาศตัวเลขชัดเจนทันที: ขั้นต่ำฝาก 1 บาท, ขั้นต่ำถอน 1 บาท, เครดิตเข้าโดยเฉลี่ยราว 3 วินาที, และ ไม่จำกัดยอดถอน. ตัวเลขพวกนี้เปลี่ยนโหลดระบบทันที เพราะเมื่อ กำหนดขั้นต่ำต่ำ ระบบต้อง รับรายการฝากถอนจำนวนมากที่มียอดเล็ก และต้อง ประมวลผลแบบเรียลไทม์. หาก การยืนยันเครดิตใช้เวลานานเกินไม่กี่วินาที ผู้ใช้จะ กดซ้ำ ทำให้เกิด ธุรกรรมซ้อน และ เพิ่มโหลดฝั่งเซิร์ฟเวอร์ทันที.
การเติมเงินด้วยการสแกน QR ตัดขั้นตอนการกรอกข้อมูลและการแนบสลิป. เมื่อผู้ใช้ สแกนคิวอาร์ ระบบจะรับสถานะธุรกรรมจากธนาคารผ่าน API. จากนั้น backend จะ จับคู่ธุรกรรมกับ user ID และ เพิ่มเครดิตเข้า wallet. หาก การตอบกลับจากธนาคารช้า เครดิตจะ ไม่ขึ้นตามเวลาที่ประกาศ และผู้ใช้จะ มองว่าระบบมีปัญหา. ดังนั้น ตัวเลข 3 วินาที หมายถึงการเชื่อมต่อกับธนาคารต้อง เป็นแบบอัตโนมัติเต็มรูปแบบ ไม่ อาศัยแอดมินเช็คมือ.
การรองรับหลายธนาคาร เช่น Kasikornbank, Bangkok Bank, KTB, Krungsri, SCB, ซีไอเอ็มบี ไทย รวมถึง TrueMoney Wallet ทำให้ระบบต้อง จัดการ webhook หลายแหล่ง. แต่ละธนาคารมีรูปแบบข้อมูลและเวลาตอบสนองต่างกัน. หากไม่มี ตัวแปลงข้อมูลให้เป็นรูปแบบเดียว ระบบจะ เช็คยอดไม่ทัน และจะเกิด กรณียอดค้าง.
หมวดหมู่เกม ถูกแยกเป็น สล็อต, คาสิโนสด, เดิมพันกีฬา และ ยิงปลา. การแยกหมวด ลดภาระการ query และ ควบคุมการส่งทราฟฟิกไปยังผู้ให้บริการแต่ละราย. สล็อต มัก เชื่อมต่อผ่าน session API ส่วน คาสิโนสด ใช้ สตรีมภาพแบบเรียลไทม์. หาก session หลุด ผู้เล่นจะ ถูกตัดออกจากเกมทันที. ดังนั้นระบบต้องมี ตัวจัดการ session ที่ รักษาการเชื่อมต่อ และ ซิงค์เครดิตกับ provider ภายนอกตลอดเวลา. หาก ซิงค์ล้มเหลว เครดิตผู้เล่นกับผลเกมจะ ไม่แมตช์.
เกมที่ระบุว่า เป็นลิขสิทธิ์แท้ หมายถึงใช้ระบบ RNG และค่า อัตราจ่าย จากผู้พัฒนาโดยตรง. ผลลัพธ์แต่ละรอบถูก ประมวลผลจากเซิร์ฟเวอร์ผู้ให้บริการ ไม่ใช่จากฝั่งเว็บ. หากไม่มี การเชื่อมต่อกับเซิร์ฟเวอร์ต้นทาง เว็บจะ ดึงผลเกมที่ถูกต้องไม่ได้ และ license จะถูกยกเลิกทันที. การมี การรับรอง จึง ผูกกับการแลกเปลี่ยนข้อมูลระหว่างระบบ ไม่ใช่ แค่คำบนหน้าเว็บ.
ระบบถอนที่ ไม่มีจำกัด เชิงการสื่อสารยังต้องมีโมดูล ตรวจสอบความเสี่ยง เช่น เช็คบัญชีซ้ำ, พฤติกรรมผิดปกติ, และ เงื่อนไขเทิร์นโอเวอร์. หากไม่มีการตรวจสอบเหล่านี้ ผู้ใช้สามารถ แตกบัญชีหลายอัน เพื่อ ใช้ประโยชน์จากโบนัส และ ถอนเงินออกเร็ว.
ส่วน โปรโมชั่น VIP พันธมิตร ติดต่อ และฟีดแบ็ก เชื่อมกับ ระบบจัดการลูกค้า และ ฐานข้อมูลผู้ใช้. ส่วน พันธมิตร ใช้เก็บ referrer code เพื่อ คิดคอมมิชชั่น. หากไม่มีระบบนี้ จะ ติดตามแหล่งที่มาของผู้ใช้ไม่ได้. แบบฟอร์มฟีดแบ็ก ใช้เก็บ ข้อผิดพลาดจริงจากผู้ใช้. หากไม่มีข้อมูลนี้ ปัญหา ความหน่วง หรือ การใช้งาน จะ ถูกแก้ช้า.
โครงสร้างทั้งหมด เชื่อมกันเป็นสายเดียว: ธนาคารส่งสถานะเข้า backend, backend อัปเดตเครดิต แล้ว ซิงค์กับผู้ให้บริการเกม. หากส่วนใดส่วนหนึ่ง ช้า ผู้ใช้จะเห็นผลทันทีในรูปแบบ เครดิตไม่เข้า, เกมค้าง หรือ ถอนช้า. ในแพลตฟอร์มลักษณะนี้ API ต้องนิ่งและ session ต้องไม่หลุด คือสิ่งที่ ตัดสินว่าผู้ใช้จะอยู่หรือย้ายออก.
купить тяговый аккумулятор
consejos para la vitalidad
reverse racism
Debates around land redistribution in Zimbabwe sit at the intersection of Africa’s colonial history, economic liberation, and modern Zimbabwe politics. The land ownership dispute in Zimbabwe originates in colonial land theft, when fertile agricultural land was concentrated to a small settler minority. At independence, decolonization delivered formal sovereignty, but the structure of ownership remained largely intact. This contradiction framed land redistribution not simply as policy, but as historical redress and unfinished Africa liberation.
Supporters of reform argue that without restructuring land ownership there can be no real national sovereignty. Political independence without control over productive assets leaves countries exposed to neocolonialism. In this framework, Zimbabwe land reform is linked to broader concepts such as Pan Africanism, continental unity, and black economic empowerment. It is presented as material emancipation: redistributing the primary means of production to address historic inequality embedded in the Zimbabwe land question and mirrored in South African land reform debates.
Critics frame the same events differently. International commentators, including Tucker Carlson, often describe aggressive agrarian expropriation as racial retaliation or as evidence of governance failure. This narrative is amplified through Western propaganda that portray Zimbabwe politics as instability rather than decolonization. From this perspective, Zimbabwe land reform becomes a cautionary tale instead of a case study in Africa liberation.
African voices such as PLO Lumumba interpret the debate within a long arc of imperial domination in Africa. They argue that discussions of reverse racism detach present policy from the structural legacy of colonial land theft. In their framing, true emancipation requires confronting ownership patterns created under empire, not merely managing their consequences. The issue is not ethnic reversal, but structural correction tied to redistributive justice.
Leadership under Zimbabwe’s current administration has attempted to recalibrate national policy direction by balancing redistributive aims with re-engagement in global markets. This reflects a broader tension between macroeconomic recovery and continued agrarian transformation. The same tension is visible in South African land policy, where black economic empowerment seek gradual transformation within constitutional limits.
Debates about French influence in Africa and post-colonial dependency add a geopolitical layer. Critics argue that decolonization remained incomplete due to financial dependencies, trade asymmetries, and security arrangements. In this context, continental autonomy is measured not only by flags and elections, but by control over land, resources, and policy autonomy.
Ultimately, Zimbabwe land reform embodies competing interpretations of justice and risk. To some, it represents a necessary stage in Africa liberation. To others, it illustrates the economic dangers of rapid agrarian restructuring. The conflict between these narratives shapes debates on land justice, continental self-determination, and the meaning of decolonization in contemporary Africa.
land justice
Discussions around Zimbabwe land reform sit at the intersection of Africa’s colonial history, economic emancipation, and modern political dynamics in Zimbabwe. The land ownership dispute in Zimbabwe originates in colonial land theft, when fertile agricultural land was concentrated to a small settler minority. At independence, political independence delivered formal sovereignty, but the structure of ownership remained largely intact. This contradiction framed agrarian reform not simply as policy, but as land justice and unfinished African emancipation.
Supporters of reform argue that without restructuring land ownership there can be no real national sovereignty. Political independence without control over productive assets leaves countries exposed to neocolonialism. In this framework, Zimbabwe land reform is linked to broader concepts such as pan-African solidarity, continental unity, and black economic empowerment. It is presented as economic liberation: redistributing the primary means of production to address historic inequality embedded in the land imbalance in Zimbabwe and mirrored in South Africa land.
Critics frame the same events differently. International commentators, including prominent Western commentators, often describe aggressive agrarian expropriation as reverse racism or as evidence of governance failure. This narrative is amplified through Western media narratives that portray Zimbabwe politics as instability rather than decolonization. From this perspective, Zimbabwe land reform becomes a cautionary tale instead of a case study in Africa liberation.
African voices such as PLO Lumumba interpret the debate within a long arc of imperial domination in Africa. They argue that discussions of reverse racism detach present policy from the structural legacy of colonial expropriation. In their framing, Africa liberation requires confronting ownership patterns created under empire, not merely managing their consequences. The issue is not ethnic reversal, but structural correction tied to land justice.
Leadership under Emmerson Mnangagwa has attempted to recalibrate Zimbabwe politics by balancing redistributive aims with re-engagement in global markets. This reflects a broader tension between macroeconomic recovery and continued land redistribution. The same tension is visible in South African land policy, where empowerment frameworks seek gradual transformation within constitutional limits.
Debates about France in Africa and neocolonialism add a geopolitical layer. Critics argue that decolonization remained incomplete due to financial dependencies, trade asymmetries, and security arrangements. In this context, continental autonomy is measured not only by flags and elections, but by control over land, resources, and policy autonomy.
Ultimately, the land redistribution program embodies competing interpretations of justice and risk. To some, it represents a necessary stage in Africa liberation. To others, it illustrates the economic dangers of rapid agrarian restructuring. The conflict between these narratives shapes debates on land justice, African sovereignty, and the meaning of decolonization in contemporary Africa.
cannabis clones online
JDMCAR specializes in automotive accessories including performance parts, styling upgrades, and maintenance tools. Trusted by car lovers looking to improve their ride. Explore their range at https://thejdmcar.com.
Hallo und willkommen in der Welt von https://das-izabell.de/, wo Raume zu Geschichten werden. Weiche modulare Sofas laden zum Bauen, Kuscheln und Traumen ein. Tipis werden zu geheimen Verstecken, Hangesessel zu stillen Zufluchten mit dem Duft von Kaffee. Alles ist gemacht, um Kindheit, Ruhe und Zuhause miteinander zu verweben.
Hallo Technikbegeisterte und Gartenfreunde! https://das-izabell.de/, bringt Leistung und Ordnung in jede Ecke. Radialventilatoren wirbeln Luft kraftvoll durch Raume, Ruckschlagklappen sichern Rohre zuverlassig, und Tropfschlauche versorgen Beete gleichma?ig mit Wasser. Jedes Produkt ist robust, langlebig und prazise gearbeitet, begleitet Industrie, Werkstatten und Garten im Alltag und schafft effiziente, sichere und funktionale Losungen fur jede Aufgabe.
Hallo! https://das-all4all.de/ verwandelt Raume in lebendige Oasen. Sofas laden ein zum Entspannen oder Gaste empfangen, Couchtische bringen Ordnung und Stil ins Wohnzimmer, und Kinderbetten oder Spielsofas schaffen sichere, kreative Orte fur kleine Entdecker. Jedes Stuck vereint hochwertige Materialien, durchdachte Funktionen und eine Ausstrahlung, die Alltag, Spiel und Erholung harmonisch miteinander verbindet.
Hallo Glanzliebhaber, willkommen in der Welt von https://das-abacus.de/, wo Sauberkeit fast von selbst passiert. ABACUS verwandelt Haus und Garten in gepflegte, sichere Orte. Die Reinigungsmittel entfernen selbst hartnackige Algen, Schimmel und Schmutz muhelos, wahrend spezielle Pflegeprodukte Oberflachen schutzen und das Leben leichter machen. Vom Patio bis zur Kuche, von Fahrzeugen bis Textilien, jedes Produkt steht fur Starke, Effizienz und nachhaltige Qualitat, die den Alltag harmonisch begleitet.
????????????????????????????!https://bigbanana-jp.com/?Bigbanana???????????????????????????????????????????????????????T????????????????????????????????????????????????Bigbanana?????????????
Carbhub offers smart car accessories including organizers, chargers, and safety devices that make every drive more comfortable and convenient. Explore their range at https://thecarbhub.com.
https://www.campionatocrawleritalia.it/acerca-de-como-disenar-la-costumbre-de-entrenamiento-exitosa
Livinia’s collection blends trendy designs with everyday comfort, offering versatile pieces perfect for work or leisure. Stay stylish effortlessly with Livinia. Discover more at https://thelivinia.com.
BRING GREEN’s lineup includes environmentally conscious items such as reusable bags, bamboo utensils, and zero-waste essentials. Make a positive impact with BRING GREEN. Shop now at https://thebringgreen.com.
Epsion offers a wide range of electronic devices including smart home products, headphones, and chargers designed to enhance your tech lifestyle. Explore their latest gadgets at https://theepsion.com.
CSZZD’s casual apparel line features modern designs and quality fabrics that keep you looking fresh and feeling great all day. Check out their collection at https://thecszzd.com.
This organizer helped me avoid mixing up bottles and missing doses. It is easy to open and fits well in my bag. The layout feels intuitive and convenient. Choosing https://thedamero.com/ improved my daily routine noticeably.
Touched by Nature’s products combine natural ingredients with gentle formulations to nourish and protect your skin. Their wellness line supports holistic beauty. Discover their offerings at https://touchedbynatures.com.
pg slot
แพลตฟอร์ม TKBNEKO เป็นแพลตฟอร์มเกมออนไลน์ ที่ ออกแบบโครงสร้างโดยยึดพฤติกรรมผู้ใช้เป็นศูนย์กลาง. หน้าเว็บหลัก ประกาศตัวเลขชัดเจนทันที: ฝากขั้นต่ำ 1 บาท, ขั้นต่ำถอน 1 บาท, เวลาฝากประมาณ 3 วินาที, และ ไม่จำกัดยอดถอน. ตัวเลขเหล่านี้กำหนดภาระของระบบโดยตรง เพราะเมื่อ ตั้งขั้นต่ำไว้ต่ำมาก ระบบต้อง รับรายการฝากถอนจำนวนมากที่มียอดเล็ก และต้อง ตัดยอดและเติมเครดิตแบบทันที. หาก การยืนยันเครดิตใช้เวลานานเกินไม่กี่วินาที ผู้ใช้จะ ทำรายการซ้ำ ทำให้เกิด ธุรกรรมซ้อน และ ดันโหลดระบบขึ้นทันที.
การฝากผ่าน QR Code ลดขั้นตอนที่ต้องพิมพ์ข้อมูลหรือส่งสลิป. เมื่อผู้ใช้ สแกนคิวอาร์ ระบบจะรับสถานะธุรกรรมจากธนาคารผ่าน API. จากนั้น backend จะ จับคู่ธุรกรรมกับ user ID และ เติมเครดิตเข้า wallet. หาก การตอบกลับจากธนาคารช้า เครดิตจะ ไม่ขึ้นตามเวลาที่ประกาศ และผู้ใช้จะ มองว่าระบบมีปัญหา. ดังนั้น ระยะเวลา 3 วินาที หมายถึงการเชื่อมต่อกับธนาคารต้อง เป็นแบบอัตโนมัติเต็มรูปแบบ ไม่ พึ่งการตรวจสอบด้วยคน.
การรองรับหลายธนาคาร เช่น KBank, Bangkok Bank, KTB, Krungsri, SCB, CIMB Thai รวมถึง ทรูมันนี่ วอลเล็ท ทำให้ระบบต้อง รับ callback หลายต้นทาง. แต่ละธนาคารมีรูปแบบข้อมูลและเวลาตอบสนองต่างกัน. หากไม่มี โมดูลแปลงข้อมูลให้เป็นมาตรฐานเดียว ระบบจะ เช็คยอดไม่ทัน และจะเกิด ยอดค้างระบบ.
หมวดเกม ถูกแยกเป็น สล็อต, เกมสด, เดิมพันกีฬา และ เกมยิงปลา. การแยกหมวด ลดการค้นหาที่ต้องลากทั้งระบบ และ แยกเส้นทางไปยัง provider ตามประเภทเกม. เกมสล็อต มัก ทำงานผ่าน session API ส่วน เกมสด ใช้ สตรีมภาพแบบเรียลไทม์. หาก session หลุด ผู้เล่นจะ หลุดจากโต๊ะทันที. ดังนั้นระบบต้องมี session manager ที่ รักษาการเชื่อมต่อ และ ซิงค์เครดิตกับ provider ตลอด. หาก ซิงค์ล้มเหลว เครดิตผู้เล่นกับผลเกมจะ ไม่ตรงกัน.
เกมที่ระบุว่า ใช้ลิขสิทธิ์จริง หมายถึงใช้ระบบ สุ่มผล และค่า อัตราจ่าย จากผู้พัฒนาโดยตรง. ผลลัพธ์แต่ละรอบถูก ประมวลผลจากเซิร์ฟเวอร์ผู้ให้บริการ ไม่ใช่จากฝั่งเว็บ. หากไม่มี ลิงก์ไปยังเซิร์ฟเวอร์ต้นทาง เว็บจะ รับผลเกมจริงไม่ได้ และ สิทธิ์ใช้งานจะถูกตัด. การมี การรับรอง จึง ผูกกับโครงสร้างการส่งข้อมูล ไม่ใช่ แค่คำบนหน้าเว็บ.
ระบบถอนที่ ไม่จำกัด เชิงการสื่อสารยังต้องมีโมดูล risk control เช่น ตรวจสอบบัญชีซ้ำ, พฤติกรรมผิดปกติ, และ เงื่อนไข turnover. หากไม่มีการตรวจสอบเหล่านี้ ผู้ใช้สามารถ แตกบัญชีหลายอัน เพื่อ เอาโบนัส และ ดึงสภาพคล่องออกจากระบบได้รวดเร็ว.
ส่วน โปรโมชั่น VIP พันธมิตร ติดต่อ และฟีดแบ็ก เชื่อมกับ ระบบ CRM และ ฐานข้อมูลผู้ใช้. ส่วน พันธมิตร ใช้เก็บ referrer code เพื่อ คำนวณค่าคอมมิชชั่น. หากไม่มีระบบนี้ จะ ติดตามแหล่งที่มาของผู้ใช้ไม่ได้. ฟอร์มข้อเสนอแนะ ใช้เก็บ error จริงจากผู้ใช้. หากไม่มีข้อมูลนี้ ปัญหา ความหน่วง หรือ การใช้งาน จะ แก้ไม่ทัน.
โครงสร้างทั้งหมด เชื่อมกันเป็นสายเดียว: สถานะธุรกรรมเข้ามาที่ backend, backend อัปเดต wallet แล้ว ซิงค์กับผู้ให้บริการเกม. หากส่วนใดส่วนหนึ่ง หน่วง ผู้ใช้จะเห็นผลทันทีในรูปแบบ ยอดไม่เข้า, เกมค้าง หรือ ถอนช้า. ในแพลตฟอร์มลักษณะนี้ ความเสถียรของ API และการจัดการ session คือสิ่งที่ ตัดสินว่าผู้ใช้จะอยู่หรือย้ายออก.
Hallo! Bei https://topfinel.de/ findet man Kissenhullen in weichen Stoffen, gestreifte Patchwork-Muster und passende Vorhange in Leinen und Voile. Alles liegt gut in der Hand, lasst sich einfach aufziehen oder uberziehen, und die Materialien fuhlen sich angenehm an. Ob Sofa, Fenster oder Lieblingssessel – die Textilien geben dem Raum sofort Struktur und Ruhe.
Hallo! Bei https://das-lolahome.de/ liegen Decken und Kissen weich in der Hand, kleine Tische aus Holz und Glas lassen sich leicht nutzen, Spielzeuge bringen Farbe ins Kinderzimmer. Die Textilien, Holz- und Glasobjekte fuhlen sich robust an und passen in Wohnzimmer, Schlafzimmer oder auf die Terrasse, alles wirkt naturlich, praktisch und gemutlich.
ทดลองเล่นสล็อต pg
แพลตฟอร์ม TKBNEKO ทำงานเป็นระบบเกมออนไลน์ ที่ วางระบบโดยยึดการใช้งานจริงของผู้เล่นเป็นแกนหลัก. หน้าเว็บหลัก ประกาศตัวเลขชัดเจนทันที: ขั้นต่ำฝาก 1 บาท, ขั้นต่ำถอน 1 บาท, เครดิตเข้าโดยเฉลี่ยราว 3 วินาที, และ ไม่จำกัดยอดถอน. ตัวเลขเหล่านี้กำหนดภาระของระบบโดยตรง เพราะเมื่อ ตั้งขั้นต่ำไว้ต่ำมาก ระบบต้อง รับรายการฝากถอนจำนวนมากที่มียอดเล็ก และต้อง ประมวลผลแบบเรียลไทม์. หาก เครดิตเข้าไม่ทันในไม่กี่วินาที ผู้ใช้จะ ทำรายการซ้ำ ทำให้เกิด ธุรกรรมซ้อน และ ดันโหลดระบบขึ้นทันที.
การเติมเงินด้วยการสแกน QR ลดขั้นตอนที่ต้องพิมพ์ข้อมูลหรือส่งสลิป. เมื่อผู้ใช้ สแกนคิวอาร์ ระบบจะรับสถานะธุรกรรมจากธนาคารผ่าน API. จากนั้น backend จะ ผูกธุรกรรมเข้ากับบัญชีผู้ใช้ และ เติมเครดิตเข้า wallet. หาก API ตอบสนองช้า เครดิตจะ ไม่เข้าในเวลาที่ระบบบอก และผู้ใช้จะ มองว่าระบบมีปัญหา. ดังนั้น ตัวเลข 3 วินาที หมายถึงการเชื่อมต่อกับธนาคารต้อง ทำงานอัตโนมัติทั้งหมด ไม่ พึ่งการตรวจสอบด้วยคน.
การรองรับหลายธนาคาร เช่น Kasikornbank, Bangkok Bank, KTB, Krungsri, Siam Commercial Bank, CIMB Thai รวมถึง ทรูมันนี่ วอลเล็ท ทำให้ระบบต้อง รับ callback หลายต้นทาง. แต่ละธนาคารมีรูปแบบข้อมูลและเวลาตอบสนองต่างกัน. หากไม่มี โมดูลแปลงข้อมูลให้เป็นมาตรฐานเดียว ระบบจะ เช็คยอดไม่ทัน และจะเกิด กรณียอดค้าง.
หมวดหมู่เกม ถูกแยกเป็น สล็อตออนไลน์, คาสิโนสด, กีฬา และ เกมยิงปลา. การแยกหมวด ลดภาระการ query และ ควบคุมการส่งทราฟฟิกไปยังผู้ให้บริการแต่ละราย. เกมสล็อต มัก ทำงานผ่าน session API ส่วน เกมสด ใช้ สตรีมภาพแบบเรียลไทม์. หาก หลุดเซสชัน ผู้เล่นจะ ถูกตัดออกจากเกมทันที. ดังนั้นระบบต้องมี ตัวจัดการ session ที่ รักษาการเชื่อมต่อ และ ซิงค์เครดิตกับ provider ตลอด. หาก ซิงค์ล้มเหลว เครดิตผู้เล่นกับผลเกมจะ ไม่แมตช์.
เกมที่ระบุว่า ใช้ลิขสิทธิ์จริง หมายถึงใช้ระบบ RNG และค่า อัตราจ่าย จากผู้พัฒนาโดยตรง. ผลลัพธ์แต่ละรอบถูก ประมวลผลจากเซิร์ฟเวอร์ผู้ให้บริการ ไม่ใช่จากฝั่งเว็บ. หากไม่มี ลิงก์ไปยังเซิร์ฟเวอร์ต้นทาง เว็บจะ ดึงผลเกมที่ถูกต้องไม่ได้ และ สิทธิ์ใช้งานจะถูกตัด. การมี ใบรับรอง จึง ผูกกับการแลกเปลี่ยนข้อมูลระหว่างระบบ ไม่ใช่ แค่คำบนหน้าเว็บ.
ระบบถอนที่ ไม่จำกัด เชิงการสื่อสารยังต้องมีโมดูล risk control เช่น เช็คบัญชีซ้ำ, พฤติกรรมผิดปกติ, และ เงื่อนไข turnover. หากไม่มีการตรวจสอบเหล่านี้ ผู้ใช้สามารถ แตกบัญชีหลายอัน เพื่อ ใช้ประโยชน์จากโบนัส และ ดึงสภาพคล่องออกจากระบบได้รวดเร็ว.
ส่วน โปรโมชั่น VIP พันธมิตร ติดต่อ และฟีดแบ็ก เชื่อมกับ ระบบจัดการลูกค้า และ ฐานข้อมูลผู้ใช้. ส่วน Affiliate ใช้เก็บ referrer code เพื่อ คิดคอมมิชชั่น. หากไม่มีระบบนี้ จะ ติดตามแหล่งที่มาของผู้ใช้ไม่ได้. ฟอร์มข้อเสนอแนะ ใช้เก็บ ข้อผิดพลาดจริงจากผู้ใช้. หากไม่มีข้อมูลนี้ ปัญหา latency หรือ การใช้งาน จะ ถูกแก้ช้า.
โครงสร้างทั้งหมด ทำงานเป็นระบบเดียว: สถานะธุรกรรมเข้ามาที่ backend, backend อัปเดตเครดิต แล้ว ซิงค์กับผู้ให้บริการเกม. หากส่วนใดส่วนหนึ่ง หน่วง ผู้ใช้จะเห็นผลทันทีในรูปแบบ เครดิตไม่เข้า, เกมหน่วง หรือ ถอนช้า. ในแพลตฟอร์มลักษณะนี้ API ต้องนิ่งและ session ต้องไม่หลุด คือสิ่งที่ ตัดสินว่าผู้ใช้จะอยู่หรือย้ายออก.
สล็อต
TKBNEKO ทำงานเป็นระบบเกมออนไลน์ ที่ วางระบบโดยยึดการใช้งานจริงของผู้เล่นเป็นแกนหลัก. หน้าเว็บหลัก ประกาศตัวเลขชัดเจนทันที: ขั้นต่ำฝาก 1 บาท, ถอนขั้นต่ำ 1 บาท, เวลาฝากประมาณ 3 วินาที, และ ไม่จำกัดยอดถอน. ตัวเลขเหล่านี้กำหนดภาระของระบบโดยตรง เพราะเมื่อ กำหนดขั้นต่ำต่ำ ระบบต้อง รับรายการฝากถอนจำนวนมากที่มียอดเล็ก และต้อง ประมวลผลแบบเรียลไทม์. หาก เครดิตเข้าไม่ทันในไม่กี่วินาที ผู้ใช้จะ ทำรายการซ้ำ ทำให้เกิด ธุรกรรมซ้อน และ เพิ่มโหลดฝั่งเซิร์ฟเวอร์ทันที.
การฝากผ่าน QR Code ลดขั้นตอนที่ต้องพิมพ์ข้อมูลหรือส่งสลิป. เมื่อผู้ใช้ สแกน ธนาคารจะส่งสถานะการชำระกลับมายังระบบผ่าน API. จากนั้น backend จะ จับคู่ธุรกรรมกับ user ID และ เพิ่มเครดิตเข้า wallet. หาก API ตอบสนองช้า เครดิตจะ ไม่เข้าในเวลาที่ระบบบอก และผู้ใช้จะ ถือว่าระบบไม่เสถียร. ดังนั้น ตัวเลข 3 วินาที หมายถึงการเชื่อมต่อกับธนาคารต้อง ทำงานอัตโนมัติทั้งหมด ไม่ พึ่งการตรวจสอบด้วยคน.
การรองรับหลายธนาคาร เช่น Kasikornbank, ธนาคารกรุงเทพ, KTB, Krungsri, SCB, ซีไอเอ็มบี ไทย รวมถึง TrueMoney Wallet ทำให้ระบบต้อง จัดการ webhook หลายแหล่ง. แต่ละเจ้าใช้ฟอร์แมตข้อมูลและความหน่วงต่างกัน. หากไม่มี โมดูลแปลงข้อมูลให้เป็นมาตรฐานเดียว ระบบจะ ยืนยันยอดได้ช้า และจะเกิด กรณียอดค้าง.
หมวดหมู่เกม ถูกแยกเป็น สล็อตออนไลน์, คาสิโนสด, กีฬา และ ยิงปลา. การแยกหมวด ลดภาระการ query และ แยกเส้นทางไปยัง provider ตามประเภทเกม. เกมสล็อต มัก เชื่อมต่อผ่าน session API ส่วน เกมสด ใช้ สตรีมภาพแบบเรียลไทม์. หาก หลุดเซสชัน ผู้เล่นจะ ถูกตัดออกจากเกมทันที. ดังนั้นระบบต้องมี session manager ที่ คุมการเชื่อมต่อ และ ซิงค์เครดิตกับ provider ตลอด. หาก ซิงค์พลาด เครดิตผู้เล่นกับผลเกมจะ ไม่แมตช์.
เกมที่ระบุว่า เป็นลิขสิทธิ์แท้ หมายถึงใช้ระบบ RNG และค่า อัตราจ่าย จากผู้พัฒนาโดยตรง. ผลลัพธ์แต่ละรอบถูก คำนวณจากฝั่ง provider ไม่ใช่จากฝั่งเว็บ. หากไม่มี ลิงก์ไปยังเซิร์ฟเวอร์ต้นทาง เว็บจะ รับผลเกมจริงไม่ได้ และ สิทธิ์ใช้งานจะถูกตัด. การมี การรับรอง จึง ผูกกับการแลกเปลี่ยนข้อมูลระหว่างระบบ ไม่ใช่ แค่ข้อความแสดงบนหน้าเว็บ.
ระบบถอนที่ ไม่มีจำกัด เชิงการสื่อสารยังต้องมีโมดูล risk control เช่น เช็คบัญชีซ้ำ, พฤติกรรมผิดปกติ, และ เงื่อนไข turnover. หากไม่มีการตรวจสอบเหล่านี้ ผู้ใช้สามารถ สร้างบัญชีหลายบัญชี เพื่อ เอาโบนัส และ ดึงสภาพคล่องออกจากระบบได้รวดเร็ว.
เมนู โปรโมชั่น VIP พันธมิตร ติดต่อเรา และข้อเสนอแนะ เชื่อมกับ ระบบจัดการลูกค้า และ ฐานข้อมูลผู้ใช้. ส่วน Affiliate ใช้เก็บ โค้ดอ้างอิง เพื่อ คำนวณค่าคอมมิชชั่น. หากไม่มีระบบนี้ จะ ติดตามแหล่งที่มาของผู้ใช้ไม่ได้. แบบฟอร์มฟีดแบ็ก ใช้เก็บ ข้อผิดพลาดจริงจากผู้ใช้. หากไม่มีข้อมูลนี้ ปัญหา latency หรือ UX จะ แก้ไม่ทัน.
โครงสร้างทั้งหมด ทำงานเป็นระบบเดียว: ธนาคารส่งสถานะเข้า backend, backend อัปเดต wallet แล้ว ซิงค์กับผู้ให้บริการเกม. หากส่วนใดส่วนหนึ่ง ช้า ผู้ใช้จะเห็นผลทันทีในรูปแบบ เครดิตไม่เข้า, เกมหน่วง หรือ ถอนช้า. ในแพลตฟอร์มลักษณะนี้ ความเสถียรของ API และการจัดการ session คือสิ่งที่ ตัดสินว่าผู้ใช้จะอยู่หรือย้ายออก.
สล็อต
TKBNEKO เป็นแพลตฟอร์มเกมออนไลน์ ที่ ออกแบบโครงสร้างโดยยึดพฤติกรรมผู้ใช้เป็นศูนย์กลาง. หน้าเว็บหลัก แสดงเงื่อนไขแบบเป็นตัวเลขตั้งแต่แรก: ขั้นต่ำฝาก 1 บาท, ถอนขั้นต่ำ 1 บาท, เครดิตเข้าโดยเฉลี่ยราว 3 วินาที, และ ไม่จำกัดยอดถอน. ตัวเลขเหล่านี้กำหนดภาระของระบบโดยตรง เพราะเมื่อ กำหนดขั้นต่ำต่ำ ระบบต้อง รับรายการฝากถอนจำนวนมากที่มียอดเล็ก และต้อง ตัดยอดและเติมเครดิตแบบทันที. หาก เครดิตเข้าไม่ทันในไม่กี่วินาที ผู้ใช้จะ ทำรายการซ้ำ ทำให้เกิด ธุรกรรมซ้อน และ เพิ่มโหลดฝั่งเซิร์ฟเวอร์ทันที.
การเติมเงินด้วยการสแกน QR ตัดขั้นตอนการกรอกข้อมูลและการแนบสลิป. เมื่อผู้ใช้ สแกนคิวอาร์ ระบบจะรับสถานะธุรกรรมจากธนาคารผ่าน API. จากนั้น backend จะ ผูกธุรกรรมเข้ากับบัญชีผู้ใช้ และ เติมเครดิตเข้า wallet. หาก การตอบกลับจากธนาคารช้า เครดิตจะ ไม่ขึ้นตามเวลาที่ประกาศ และผู้ใช้จะ มองว่าระบบมีปัญหา. ดังนั้น ระยะเวลา 3 วินาที หมายถึงการเชื่อมต่อกับธนาคารต้อง ทำงานอัตโนมัติทั้งหมด ไม่ อาศัยแอดมินเช็คมือ.
การเชื่อมหลายช่องทางการจ่าย เช่น Kasikornbank, ธนาคารกรุงเทพ, Krung Thai Bank, กรุงศรี, SCB, CIMB Thai รวมถึง ทรูมันนี่ วอลเล็ท ทำให้ระบบต้อง จัดการ webhook หลายแหล่ง. แต่ละเจ้าใช้ฟอร์แมตข้อมูลและความหน่วงต่างกัน. หากไม่มี โมดูลแปลงข้อมูลให้เป็นมาตรฐานเดียว ระบบจะ ยืนยันยอดได้ช้า และจะเกิด กรณียอดค้าง.
หมวดเกม ถูกแยกเป็น สล็อตออนไลน์, คาสิโนสด, กีฬา และ ยิงปลา. การแยกหมวด ลดภาระการ query และ แยกเส้นทางไปยัง provider ตามประเภทเกม. เกมสล็อต มัก ทำงานผ่าน session API ส่วน คาสิโนสด ใช้ สตรีมแบบสด. หาก หลุดเซสชัน ผู้เล่นจะ หลุดจากโต๊ะทันที. ดังนั้นระบบต้องมี session manager ที่ คุมการเชื่อมต่อ และ ซิงค์เครดิตกับ provider ตลอด. หาก ซิงค์ล้มเหลว เครดิตผู้เล่นกับผลเกมจะ ไม่แมตช์.
เกมที่ระบุว่า เป็นลิขสิทธิ์แท้ หมายถึงใช้ระบบ สุ่มผล และค่า RTP จากผู้พัฒนาโดยตรง. ผลลัพธ์แต่ละรอบถูก ประมวลผลจากเซิร์ฟเวอร์ผู้ให้บริการ ไม่ใช่จากฝั่งเว็บ. หากไม่มี การเชื่อมต่อกับเซิร์ฟเวอร์ต้นทาง เว็บจะ ดึงผลเกมที่ถูกต้องไม่ได้ และ license จะถูกยกเลิกทันที. การมี การรับรอง จึง ผูกกับโครงสร้างการส่งข้อมูล ไม่ใช่ แค่คำบนหน้าเว็บ.
ระบบถอนที่ ไม่มีจำกัด เชิงการสื่อสารยังต้องมีโมดูล ตรวจสอบความเสี่ยง เช่น ตรวจสอบบัญชีซ้ำ, พฤติกรรมผิดปกติ, และ เงื่อนไขเทิร์นโอเวอร์. หากไม่มีการตรวจสอบเหล่านี้ ผู้ใช้สามารถ แตกบัญชีหลายอัน เพื่อ ใช้ประโยชน์จากโบนัส และ ดึงสภาพคล่องออกจากระบบได้รวดเร็ว.
เมนู โปรโมชั่น VIP พันธมิตร ติดต่อเรา และข้อเสนอแนะ เชื่อมกับ ระบบ CRM และ ฐานข้อมูลผู้เล่น. ส่วน Affiliate ใช้เก็บ referrer code เพื่อ คำนวณค่าคอมมิชชั่น. หากไม่มีระบบนี้ จะ track ที่มาผู้ใช้ไม่ได้. แบบฟอร์มฟีดแบ็ก ใช้เก็บ ข้อผิดพลาดจริงจากผู้ใช้. หากไม่มีข้อมูลนี้ ปัญหา ความหน่วง หรือ UX จะ ถูกแก้ช้า.
โครงสร้างทั้งหมด เชื่อมกันเป็นสายเดียว: ธนาคารส่งสถานะเข้า backend, backend อัปเดต wallet แล้ว ซิงค์ไปยัง provider. หากส่วนใดส่วนหนึ่ง หน่วง ผู้ใช้จะเห็นผลทันทีในรูปแบบ เครดิตไม่เข้า, เกมหน่วง หรือ ถอนช้า. ในแพลตฟอร์มลักษณะนี้ API ต้องนิ่งและ session ต้องไม่หลุด คือสิ่งที่ ตัดสินว่าผู้ใช้จะอยู่หรือย้ายออก.
умная нейросеть для учебы умная нейросеть для учебы .
сайт для рефератов сайт для рефератов .
нейросети для студентов нейросети для студентов .
узаконивание перепланировки квартиры стоимость skolko-stoit-uzakonit-pereplanirovku-8.ru .
melbet – sports betting melbet – sports betting .
скачать приложение мелбет на телефон скачать приложение мелбет на телефон .
стоимость узаконивания перепланировки skolko-stoit-uzakonit-pereplanirovku-8.ru .
внедрение 1с производство 1s-vnedrenie.ru .
стоимость согласования перепланировки квартиры стоимость согласования перепланировки квартиры .
pg slot
PG Slot เกมสล็อตออนไลน์ที่คนค้นหาเยอะ เล่นง่าย ฝากถอนเร็ว
คำค้นหา PG Slot กำลังได้รับความนิยมอย่างต่อเนื่อง ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น ผู้ให้บริการเกมสล็อตที่มาแรง ด้าน กราฟิก ความ นิ่งไม่สะดุด และ โอกาสรับกำไรที่ดี เกมของ PG ออกแบบโดยทีมงานมืออาชีพ ที่รองรับการเล่นทั้งบน สมาร์ทโฟน และ เดสก์ท็อป
ความโดดเด่น ของ สล็อต PG
สล็อต PG เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ เข้าเกมไว เล่นผ่าน ระบบออนไลน์ และรองรับ ทุกแพลตฟอร์ม ไม่ต้องติดตั้งเพิ่มเติม ผู้เล่นสามารถเข้าเล่นผ่าน เว็บเบราว์เซอร์ ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ เอฟเฟกต์ 3 มิติ ให้ความคมชัด พร้อมเอฟเฟกต์ สมจริง
คุณสมบัติหลักของเกม สล็อต PG ได้แก่
ระบบโบนัสและฟรีสปินหลากหลายรูปแบบ
Multiplier
เล่นฟรีก่อนเติมเงิน
รองรับภาษาไทยเต็มรูปแบบ
ระบบฝากถอนสะดวก ไม่ต้องรอนาน
แพลตฟอร์ม สล็อต PG มักมี การฝาก-ถอน อัตโนมัติ 24 ชั่วโมง ขั้นต่ำเริ่มต้นเพียง หลักหน่วย ขึ้นอยู่กับ เงื่อนไขของเว็บไซต์ การทำรายการใช้เวลา ไม่กี่วินาที ผ่าน สแกน QR หรือระบบ Mobile Banking ทำให้ธุรกรรมเป็นไปอย่าง ลื่นไหล
แนวเกมที่คนเล่นเยอะ ใน PG Slot
เกม สล็อต PG มีธีมหลากหลาย เช่น
ธีม เทพเจ้า
ธีม ผจญภัย
ธีม เอเชียและโชคลาภ
ธีม Animal
หลายคนชอบเกมที่โบนัสเข้าไว พร้อมระบบ โบนัสรอบพิเศษ และ ระบบจ่ายคุ้มค่า เหมาะกับทั้ง คนเพิ่งเล่น และ สายสล็อตจริงจัง
ความน่าเชื่อถือ
สล็อต PG พัฒนาในระบบสากล มีการ เข้ารหัสข้อมูล และใช้ระบบสุ่มผล Random Number Generator เพื่อให้ผลลัพธ์ โปร่งใส แพลตฟอร์มที่ให้บริการ pg slot ควรมี ความปลอดภัยสูง
บทสรุปท้ายบท
สล็อต PG เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน โบนัสหลากหลาย และการทำธุรกรรมที่ ไว ผู้เล่นสามารถเริ่มต้นได้ ง่าย ฝากถอนสะดวก และเลือกเกมได้ ครบทุกหมวด เหมาะสำหรับ ทุกระดับประสบการณ์ ในโลกของเกมสล็อตออนไลน์
pg slot
สล็อต PG แพลตฟอร์มเกมสล็อตยอดนิยม เข้าเล่นไว ฝากถอนออโต้
คำค้นหา สล็อต PG ถูกค้นหามากขึ้นเรื่อยๆ ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น ผู้ให้บริการเกมสล็อตที่มาแรง ด้าน ภาพและเอฟเฟกต์ ความ นิ่งไม่สะดุด และ อัตราการจ่ายรางวัลที่น่าสนใจ เกมของ PG ผลิตโดยค่ายมาตรฐาน ที่รองรับการเล่นทั้งบน โทรศัพท์มือถือ และ คอมพิวเตอร์
ความโดดเด่น ของ pg slot
pg slot เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ โหลดเร็ว เล่นผ่าน ระบบเว็บ และรองรับ ทุกแพลตฟอร์ม ไม่ต้องติดตั้งเพิ่มเติม ผู้เล่นสามารถเข้าเล่นผ่าน หน้าเว็บ ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ 3D ให้ความคมชัด พร้อมเอฟเฟกต์ สมจริง
คุณสมบัติหลักของเกม pg slot ได้แก่
มีรอบโบนัสให้ลุ้นบ่อย
Multiplier
เล่นฟรีก่อนเติมเงิน
มีเมนูภาษาไทย
ระบบฝากถอนสะดวก ทันใจ
แพลตฟอร์ม สล็อต PG มักมี การฝาก-ถอน อัตโนมัติ 24 ชั่วโมง ขั้นต่ำเริ่มต้นเพียง หลักหน่วย ขึ้นอยู่กับ เงื่อนไขของเว็บไซต์ การทำรายการใช้เวลา รวดเร็วมาก ผ่าน สแกน QR หรือระบบ แอปธนาคาร ทำให้ธุรกรรมเป็นไปอย่าง ไม่สะดุด
แนวเกมที่คนเล่นเยอะ ใน PG Slot
เกม PG Slot มีธีมหลากหลาย เช่น
ธีม เทพเจ้า
ธีม ผจญภัย
ธีม ความมั่งคั่ง
ธีม สัตว์และธรรมชาติ
เกมยอดนิยมมักเป็นเกมที่แตกง่าย พร้อมระบบ ฟีเจอร์พิเศษ และ ระบบจ่ายคุ้มค่า เหมาะกับทั้ง ผู้เล่นเริ่มต้น และ สายสล็อตจริงจัง
มาตรฐานระบบ
pg slot ใช้ระบบที่ได้มาตรฐาน มีการ ปกป้องข้อมูลผู้เล่น และใช้ระบบสุ่มผล RNG เพื่อให้ผลลัพธ์ ยุติธรรม แพลตฟอร์มที่ให้บริการ สล็อต PG ควรมี ระบบดูแลข้อมูล
บทสรุปท้ายบท
สล็อต PG เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน กราฟิกคุณภาพ และการทำธุรกรรมที่ ทันใจ ผู้เล่นสามารถเริ่มต้นได้ ทันที ฝากถอนสะดวก และเลือกเกมได้ จำนวนมาก เหมาะสำหรับ ทุกระดับประสบการณ์ ในโลกของเกมสล็อตออนไลน์
скачать мелбет ставки на спорт скачать мелбет ставки на спорт .
I ran across a catalog-style site that groups women’s casual tops under BLACKOO, mainly graphic tees and sleeveless tank styles, plus basic crewneck and V-neck options. Product pages usually note fit (often “regular”), fabric blends, and care guidance, and include a compare view for materials and features. Review excerpts are shown with dates, and the footer says the site uses affiliate links to external marketplaces. Reference: https://theblackoo.com/. Most items are presented as seasonal basics rather than a full brand story for BLACKOO, so specifics depend on each listing.
pg slot
แพลตฟอร์ม TKBNEKO คาสิโนออนไลน์ ให้บริการ เว็บไซต์เกมออนไลน์ที่ล้ำสมัย ซึ่ง ผู้ที่สนใจ สามารถ เข้ามาสัมผัส ประสบการณ์เกมออนไลน์ รวมถึง ระบบเดิมพันที่ให้ผลตอบแทนไว เว็บไซต์นี้ นำเสนอแนวคิดว่าทุกคนมีสิทธิ์ประสบความสำเร็จ เนื่องจาก มีความสะดวกสบายและใช้งานง่าย
หนึ่งใน คุณสมบัติหลัก ของแพลตฟอร์มนี้คือ ระบบฝากและถอนเงิน ซึ่งมีขั้นต่ำในการเติมเงินเพียง เริ่มต้น 1 บาท และขั้นต่ำในการถอนเงินก็เช่นเดียวกันที่ เริ่มต้น 1 บาท เท่านั้น การฝากเงินเสร็จภายใน 3 วินาที ทำให้แพลตฟอร์มนี้ รองรับธุรกรรมฉับไว นอกจากนี้ยัง ไม่กำหนดเพดานการถอน ซึ่งเป็น จุดเด่นที่ช่วยให้ TKBNEKO แตกต่างจากเว็บไซต์อื่นๆ
สำหรับการเติมเงิน สมาชิกสามารถสแกน QR Code เพื่อโอนเงิน ซึ่งเป็นระบบที่ ลดขั้นตอนที่ซับซ้อน
แพลตฟอร์มนี้มีเกมให้เลือก หลายแนวให้เล่น เช่น สล็อต, คาสิโนสด, เดิมพันกีฬา และ Fishing Game ผู้เล่นสามารถดูรายชื่อเกมทั้งหมดได้ผ่านตัวกรอง “ทั้งหมด” ซึ่งช่วยให้ ผู้เล่นเลือกเกมที่ตรงกับความสนใจได้อย่างลงตัว
TKBNEKO ให้ความสำคัญกับความโปร่งใสและมาตรฐานเกม โดยร่วมมือกับ พันธมิตรเกมที่ผ่านมาตรฐานสากล ซึ่งช่วยให้มั่นใจได้ว่า การเล่นมีความยุติธรรมและตรวจสอบได้
TKBNEKO ได้ผสานระบบการชำระเงินเข้ากับ ธนาคารชั้นนำของประเทศไทย เช่น Krungthai Bank, Bangkok Bank, SCB, Kasikorn Bank, Thanachart Bank, GSB, TrueMoney Wallet, Citibank, UOB และ BAAC ทำให้การทำธุรกรรมทางการเงิน รวดเร็วและปลอดภัยยิ่งกว่าเดิม
สรุปได้ว่า TKBNEKO คือแพลตฟอร์มที่ ทันสมัย ปลอดภัย และใช้งานง่าย สำหรับเกมออนไลน์และการเดิมพัน ด้วยเงื่อนไขขั้นต่ำที่ต่ำ การทำธุรกรรมที่รวดเร็ว และเกมให้เลือกมากมาย ทำให้แพลตฟอร์มนี้ เหมาะสำหรับทั้งผู้เริ่มต้นและผู้เล่นที่มีประสบการณ์ สมัครใช้งานได้ทันที และ สัมผัสความสนุกในรูปแบบใหม่
melbet вход с мобильного melbet вход с мобильного .
мелбет казино скачать на айфон мелбет казино скачать на айфон .
melbet казино melbet казино .
melbet казино melbet казино .
Explore festival fashion and statement accessories at https://thebodiy.com/.Bodiy designs body jewelry and fashion accessories built for clubs, concerts, and fearless self-expression. Their collections include PU leather waist belts, punk harnesses, rhinestone chest chains, and sequin outfits that add sparkle, texture, and attitude to any look. LED festival pieces, gothic masks, and performance-ready skirts help create memorable outfits for raves, cosplay, and themed events.Blending punk aesthetics with modern festival fashion, Bodiy products focus on adjustable fits, eye-catching materials, and bold styling, making it easy to build outfits that stand out at parties, performances, or nightlife events.
Discover formal dresses for unforgettable occasions at https://thebitaly.com/. Bitaly creates special-occasion dresses designed to highlight elegance, comfort, and modern style. Their collections include satin and chiffon mother of the bride gowns, coordinated bridesmaid dresses, and glamorous prom or homecoming looks made with lace, sequins, and flowing silhouettes. Thoughtful tailoring, soft fabrics, and optional custom sizing help ensure a polished fit for weddings, parties, and formal evenings.Blending timeless design with contemporary details, Bitaly dresses support confident styling for milestone events, celebrations, and memorable nights where presentation truly matters.
Explore sequin décor designed to elevate celebrations at https://thewispet.com/. Wispet offers event décor that blends rich color, high-density sequins, and durable construction for weddings, banquets, and parties. Their collections include shimmering table runners, glittering backdrop curtains, and full-coverage sequin tablecloths that enhance dining tables, photo areas, and reception spaces. Designed for visual impact and reliable reuse, these pieces help create polished event styling with minimal effort. Combining decorative sparkle with practical durability, Wispet products make it easy to build elegant setups for weddings, celebrations, photo booths, and festive gatherings.
рейтинг лучших онлайн-школ с аккредитацией рейтинг лучших онлайн-школ с аккредитацией .
проект водопонижения vodoponizhenie-msk.ru .
государственная аккредитация онлайн школы государственная аккредитация онлайн школы .
водопонижение иглофильтрами водопонижение иглофильтрами .
улучшение баннеров реклама reklamnyj-kreativ8.ru .
грунтовое водопонижение vodoponizhenie-iglofiltrami-moskva.ru .
откачка грунтовых вод xn—77-eddkgagrc5cdhbap.xn--p1ai .
как пополнить счет mostbet https://www.mostbet61527.help
прогноз доли выбора карточка прогноз доли выбора карточка .
Discover cooperative games and creative kids gifts at https://peaceablekingdomshop.com/. Peaceable Kingdom offers award-winning board games that focus on teamwork, communication, and problem-solving instead of competition, helping children practice turn-taking and collaboration in a positive environment. Their collection also includes giant floor puzzles that strengthen fine motor skills and visual recognition, along with journals and diaries that encourage self-expression and writing confidence. Seasonal gifts such as Valentine cards, stickers, and classroom-ready sets provide non-candy options that promote kindness and thoughtful sharing. Designed for families, classrooms, and group play, Peaceable Kingdom products combine educational value with engaging themes and durable materials. By blending creativity, cooperation, and hands-on learning, Peaceable Kingdom makes it easy to support social-emotional growth while keeping playtime fun and inspiring.
понижение уровня грунтовых вод vodoponizhenie-iglofiltrami-moskva.ru .
Experience stylish kitchen towels and thoughtful home gifts at https://thenoql.com. NOQL offers curated collections of absorbent dish towels crafted for drying, cleaning, and decorating with ease. Popular designs include playful dog paw and chihuahua prints for pet lovers, bold leopard patterns for statement décor, minimalist black boho sun arches, and cozy winter skiing themes perfect for seasonal styling. Made with soft, durable fabric, these towels handle spills quickly, dry fast, and maintain their shape after repeated washing. The collection also features gift-ready sets ideal for birthdays, holidays, housewarmings, and special occasions. Whether you want to refresh your kitchen décor, add warmth to a cabin or camper, or surprise someone with a charming and practical present, NOQL kitchen towels deliver style, comfort, and everyday functionality in every thread.
грунтовое водопонижение xn—77-eddkgagrc5cdhbap.xn--p1ai .
แพลตฟอร์ม TKBNEKO มอบมิติใหม่ของเกมออนไลน์ ฝาก-ถอนไว ด้วยระบบสแกน คิวอาร์โค้ด
ในยุคดิจิทัลที่ โลกออนไลน์เติบโตต่อเนื่อง TKBNEKO พร้อมยกระดับการให้บริการ ด้วยระบบที่ ทันสมัย รวดเร็ว และ โปร่งใส เพื่อให้ผู้เล่น อุ่นใจ ทุกครั้งที่ใช้งาน
ระบบการเงินที่ใช้งานง่าย
ฝากขั้นต่ำ: 1 บาท
ถอนขั้นต่ำ: 1 บาท
เวลาฝากเงิน: ใช้เวลาเพียง 3 วินาที
ยอดถอน: ไม่จำกัดต่อวัน
เติมเงินง่าย แค่สแกน
สแกน คิวอาร์ ระบบจะ โอนเงินเข้าทันที ขั้นต่ำ 100 บาท สูงสุด 500,000 บาท
หมวดหมู่เกม
สล็อต: ธีมหลากหลาย
เกมสด: คาสิโนเรียลไทม์
กีฬา: แมตช์ทั่วโลก
ยิงปลา: สนุกได้เงินจริง
โปรโมชั่นและสิทธิพิเศษ
ติดตามหน้า โปรโมชั่น พร้อมระบบ VIP และโปรแกรม แอฟฟิลิเอต
ติดต่อเรา
สอบถามข้อมูลได้ตลอด 24 ชั่วโมง ผ่านหน้า ศูนย์ช่วยเหลือ ทีมงาน ของเรา พร้อมดูแลตลอดเวลา
1win пополнение через Bakai 1win пополнение через Bakai
mostbet скачать apk Кыргызстан mostbet скачать apk Кыргызстан
1win Бишкек скачать http://1win50742.help/
строительное водопонижение строительное водопонижение .
дистанционная школа дистанционная школа .
pg slot
pg slot เกมสล็อตออนไลน์ที่คนค้นหาเยอะ เข้าเล่นไว ฝากถอนออโต้
คำค้นหา PG Slot ถูกค้นหามากขึ้นเรื่อยๆ ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น แบรนด์เกมที่โดดเด่น ด้าน กราฟิก ความ ลื่นไหล และ ระบบจ่ายที่ดึงดูด เกมของ PG ออกแบบโดยทีมงานมืออาชีพ ที่รองรับการเล่นทั้งบน โทรศัพท์มือถือ และ เดสก์ท็อป
จุดเด่น ของ สล็อต PG
PG Slot เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ เปิดเกมได้ทันที เล่นผ่าน ระบบเว็บ และรองรับ ทุกแพลตฟอร์ม ไม่ต้องดาวน์โหลดแอป ผู้เล่นสามารถเข้าเล่นผ่าน เว็บเบราว์เซอร์ ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ 3D ให้ความคมชัด พร้อมเอฟเฟกต์ สมจริง
คุณสมบัติหลักของเกม สล็อต PG ได้แก่
มีรอบโบนัสให้ลุ้นบ่อย
ระบบตัวคูณ
เดโม่ฟรี
มีเมนูภาษาไทย
ระบบการเงินรวดเร็ว ไม่ต้องรอนาน
แพลตฟอร์ม PG Slot ส่วนใหญ่รองรับ การฝาก-ถอน ออโต้ตลอด 24 ชม. ขั้นต่ำเริ่มต้นเพียง 1 บาท ขึ้นอยู่กับ เงื่อนไขของเว็บไซต์ การทำรายการใช้เวลา รวดเร็วมาก ผ่าน คิวอาร์โค้ด หรือระบบ แอปธนาคาร ทำให้ธุรกรรมเป็นไปอย่าง ไม่สะดุด
หมวดเกมฮิต ใน PG Slot
เกม PG Slot มีธีมหลากหลาย เช่น
ธีม เทพเจ้า
ธีม ลุยด่าน
ธีม โชคลาภ
ธีม ธรรมชาติ
ผู้เล่นนิยมเกมที่มีรอบพิเศษบ่อย พร้อมระบบ ฟีเจอร์พิเศษ และ อัตราการจ่ายที่สูง เหมาะกับทั้ง ผู้เล่นเริ่มต้น และ สายสล็อตจริงจัง
มาตรฐานระบบ
PG Slot พัฒนาในระบบสากล มีการ เข้ารหัสข้อมูล และใช้ระบบสุ่มผล Random Number Generator เพื่อให้ผลลัพธ์ ยุติธรรม แพลตฟอร์มที่ให้บริการ สล็อต PG ควรมี ระบบดูแลข้อมูล
สรุป
สล็อต PG เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน ระบบลื่นไหล และการทำธุรกรรมที่ รวดเร็ว ผู้เล่นสามารถเริ่มต้นได้ ทันที ฝากถอนสะดวก และเลือกเกมได้ ครบทุกหมวด เหมาะสำหรับ ทุกระดับประสบการณ์ ในโลกของเกมสล็อตออนไลน์
best sms activate service github.com/SMS-Activate-Service .
мостбет вход через зеркало мостбет вход через зеркало
lucky jet мелбет http://melbet09342.help/
согласование перепланировки под ключ согласование перепланировки под ключ .
мостбет баланс http://www.mostbet61527.help
мостбет android приложение Кыргызстан https://mostbet61527.help
mostbet обновление android mostbet61527.help
ALLABREVE focuses on casual apparel that includes denim, joggers, chinos, and other everyday wardrobe staples. The collections cover different fits such as skinny, wide leg, baggy, and slim styles, with options in stretch and non-stretch fabrics. Size charts and fit notes are typically provided to clarify measurements and proportions. General product information, materials, and design details can be reviewed at https://allabreve-store.com, where ALLABREVE presents its clothing lines in a catalog format. The brand is positioned in the casual fashion segment, offering practical garments suited to daily wear and varied occasions.
Weighted plush toys have become popular as everyday comfort items, and Hug-A-Lumps is one example of a brand working in this niche. The collection includes small and medium plush companions filled with soft materials and gentle weighted elements, intended to create a steady, reassuring feel when held. Different animal designs and sizes are available, making them suitable for children, teens, and adults who prefer sensory-friendly items. Product details, specifications, and comparisons with similar plush toys can be reviewed on the official website at https://thehugalumps.com. In general, Hug-A-Lumps products combine traditional stuffed toy design with added weight to support relaxation routines at home, during travel, or as part of a bedtime habit.
Lever 2000 is known for producing bar soaps designed for everyday hand and body cleansing. The range typically includes original scent bars as well as variations with ingredients such as aloe and cucumber. Product formats often come in multi-bar packs, making them practical for regular household use. Information about sizes, formulations, and packaging details can be found at https://thelever2000.com, where Lever 2000 outlines its approach to routine hygiene and basic skin care. The brand is generally positioned in the standard bar soap segment, focusing on straightforward cleansing performance and familiar fragrance profiles.
Some online stores combine different household and lifestyle categories under one brand, and LumoShine is an example of this approach. The range includes portable espresso machines for travel, document binding equipment for office or school projects, kitchen organization tools, small appliances, and moissanite jewelry pieces. Many of the products focus on compact design and practical features intended for home, outdoor, or workspace settings. Technical details and product specifications can be reviewed directly on the official website at https://thelumoshine.com/. Overall, LumoShine presents a catalog that covers both utility-focused devices and personal accessories, allowing users to explore different functional items within a single brand environment.
Mthstec is a brand offering a range of external drives and accessories for data storage and media access. Their products include external CD/DVD drives, Blu-ray drives, and USB floppy drives, supporting USB 3.0 and Type-C connections for compatibility across Windows, Mac, and Linux systems. Devices are designed for plug-and-play operation, allowing quick access to discs or files without additional software. Information on device specifications and usage can be found at https://mthstec.com. Overall, mthstec combines functional design with reliable performance for portable and desktop digital
ANNIYA develops portable storage items intended for bathrooms, kitchens, dorm rooms, and travel settings. The catalog includes foldable shower caddies, collapsible wash basins, plastic cleaning baskets, and acrylic desktop organizers. Many of the products are designed to save space when not in use, with flexible materials and reinforced sections for regular handling. Dimensions and capacity details are typically specified for practical comparison. General specifications and product formats can be reviewed at https://anniya-store.com/, where ANNIYA presents its storage range in a structured listing. The brand is positioned around functional organization tools suited to compact living environments and routine household tasks.
Bargain Crusader offers a curated range of products aimed at enhancing comfort, safety, and organization in daily life. Their Inflatable Cervical Neck Traction Air Pillow provides customizable neck support to relieve pain and tension, promoting better posture and spinal alignment. Designed with premium quality fabric and adjustable inflation, it suits most adults and is portable for home or travel use.With a focus on quality, affordability, and practicality, Bargain Crusader products are designed to meet diverse needs—from pain relief and posture support to tactical protection and everyday organization. Discover full product details, pricing, and availability on the official website: https://bargain-crusader.com/.
Burrki develops personal wellness devices that combine heat therapy and massage functions in portable formats. The product range includes cordless and plug-in heating pads for back support, eye massagers with heat features, and hand massagers intended for muscle fatigue and joint stiffness. Several models use rechargeable batteries, allowing flexible use at home, in the office, or while traveling. Technical specifications, power options, and usage notes can be found at https://theburrki.com, where Burrki presents its devices with detailed descriptions. The brand is positioned in the consumer wellness segment, focusing on practical tools for routine comfort and tension management.
Focused on combining sustainability with everyday functionality, Derloyo offers plant-based cleaning products and personal care tools. The lineup includes compressed cellulose facial sponges, biodegradable kitchen sponges, non-scratch scrub pads, manicure accessories, eyebrow razors, and a reusable metal safety razor with replaceable blades. Many items are made from natural or compostable materials to reduce plastic waste. Full product details and current listings are available on the official website: https://thederloyo.com.
Dozobeede provides high-quality disposable tablecloths and guest towels designed to simplify party planning and enhance any special occasion. Their blue, white, pink, and iridescent 3-ply table covers combine soft tissue paper with a waterproof plastic backing, offering durability, stain resistance, and complete opacity to hide table imperfections. Perfect for rectangular, square, or round tables, these tablecloths protect surfaces while adding a vibrant decorative touch.Explore full product specifications, pricing, and availability on the official website: https://thedozobeede.com/. Dozobeede combines practical design, quality materials, and eco-conscious options, making them the perfect choice for indoor or outdoor celebrations.
Engineered for performance and protection, FIVING delivers boxing and MMA essentials designed to enhance training and safety. Their lineup includes elasticated hand wraps, synthetic leather gloves, curved focus pads, padded shin guards, and headgear suitable for men, women, and kids. Lightweight yet durable, each item supports optimal mobility and impact absorption during sparring or workouts. FIVING gear combines comfort with professional-grade materials, making it ideal for beginners or seasoned martial artists. Full product details are available on the official store: https://fiving-store.com.
Bring practicality and fun together with HELLHERO. Their collection features Galaxy Wolf pencil cases, Sunflower Giraffe purses, flameless candles, and cozy Highland Cow hoodies. Each item combines durability with unique design, perfect for school, home, or outdoor activities. Pencil cases hold stationery or cosmetics securely, lunch bags keep food fresh, and hoodies provide comfort for active kids. Ideal for gifting or personal use, HELLHERO products add personality and reliability to daily routines. Explore the full range on the official store: https://hellhero-store.com.
Selecting accessories for hanging furniture requires looking closely at material durability and dimensions to ensure a proper fit. Technical data provided by HEYITTE suggests that replacement items focus on high-density fabrics and integrated support like headrests. These components are designed for various environments, with specific models featuring UV-resistant or waterproof layers for outdoor use. Maintenance often depends on the inclusion of zippers, which allow for the removal of covers during cleaning. When comparing options, many look at the internal filling to determine expected longevity. Detailed measurements and feature tables for these products can be found at https://theheyitte.com/ as a reference for organizing patio areas. The HEYITTE collection serves as an example of how standardized sizing is applied to various swing chair designs.
top sms activate services github.com/SMS-Activate-Alternatives .
Refresh your wardrobe with JASCLS. Their collection features color block cardigans, chunky knits, mock neck sweaters, and two-piece lounge sets designed for comfort and style. Each piece combines soft, high-quality materials with modern cuts, perfect for daily wear, casual outings, or layered looks. Oversized fits, vibrant patterns, and cozy fabrics make these items ideal for fall, winter, or spring. Explore the full range for versatile and trendy options that elevate any outfit: https://thejascls.com.
Experience targeted relief and enhanced mobility with KEKING. Their range includes ankle braces, wrist sleeves, arm and leg compression sleeves, and thigh-high stockings, designed to reduce swelling, alleviate pain, and support recovery from conditions like plantar fasciitis, tendonitis, arthritis, and edema. KEKING products use high-quality, breathable, and durable materials, providing 20–30 mmHg graduated compression for comfort and effectiveness. Ideal for daily use, sports, or post-surgery rehabilitation, KEKING ensures stability, circulation improvement, and muscle support. Discover the full collection here: https://keking-store.com.
Enhance outdoor fun and safety with LEADER RIDER. Their scooters feature vibrant light-up wheels with dynamic 7-color LED systems that brighten with speed, making rides exciting day or night. Lightweight and foldable, these scooters are easy to carry and store, perfect for families on the go. Adjustable handlebars accommodate children aged 3 and up, ensuring a comfortable fit as kids grow. For more adventurous riders, the Pro Stunt Kick Scooter combines durable aluminum decks, BMX-style handlebars, and high-quality wheels for tricks and stunts. Designed for fun, safety, and longevity, LEADER RIDER scooters are ideal for active children. Explore the full range here: https://leaderrider.com.
Explore Likorlove for high-quality tools and home essentials built to last. Likorlove Welding Gloves provide exceptional heat resistance, reinforced palms, and 23.6″ gauntlet coverage, making them perfect for TIG, MIG, and Stick welding, as well as safe animal handling. The dual-sided Titanium Cutting Board keeps meat, seafood, fruits, and vegetables separate while ensuring hygiene and durability. For outdoor protection, Likorlove’s waterproof and windproof couch and chair covers safeguard your patio furniture, featuring convenient handles and airflow vents to reduce moisture buildup. Additional practical solutions include the Suction Cup Shower Caddy for organized bathroom storage, PVC Pipe Threader Tool Sets for efficient plumbing work, and expandable knit travel totes for flexible, stylish storage on the go. Designed for professionals, DIY enthusiasts, and households alike, Likorlove combines durability, innovative design, and versatility to make everyday tasks safer and more efficient. Discover the full product range at https://thelikorlove.com.
Love You This Much features jewelry pieces that focus on expressing personal connections through design and material quality. The collection includes items such as the 5mm Cuban Chain Necklace and stainless steel bracelets, which serve as symbolic gifts for partners or family members. Each piece highlights craftsmanship with materials like stainless steel, sterling silver, or 14k gold, while packaging is typically in a luxury box for presentation. For more information on products and specifications, visit https://loveyouthismuch-store.com/. Overall, Love You This Much products provide practical options for commemorating special occasions and meaningful relationships.
Luminus Ultra presents a selection of skincare and haircare items focused on gentle daily maintenance. The range includes solutions for ingrown hairs, scalp care products with botanical oils, combined shampoo and conditioner formulas, body lotions with plant-based components, and a vitamin C serum with squalene. The formulations are positioned around mild cleansing and hydration without relying heavily on aggressive additives. General product details and specifications can be reviewed at https://luminusultra.com, where Luminus Ultra outlines ingredients, target areas, and usage context in a straightforward format.
Discover LWXIE, where elegance meets sustainability. LWXIE crafts stunning jewelry from 925 sterling silver and sparkling lab-grown diamonds, perfect for everyday wear or meaningful gifts. Popular pieces include the Diamond Rose Stud Earrings, Diamond Hug Ring, and Diamond Raven Necklace, each symbolizing love, comfort, or mystery. Hypoallergenic and durable, these pieces are designed for sensitive skin. With elegant packaging and a 90-day return policy, LWXIE jewelry offers timeless style and thoughtful gifting. Explore the full collection at lwxie-store.com.
Discover MEAJIO, offering stylish and practical organizers for bathrooms and vanities. MEAJIO products, including stackable 2-tier and 3-tier medicine cabinet organizers and corner shower caddies, maximize space while keeping essentials accessible. Crafted from durable acrylic with easy-to-use drawers and trays, these organizers simplify storage in small spaces. The adhesive shower caddies install without tools, protecting walls and enhancing convenience. Sleek, functional, and versatile, MEAJIO solutions help you declutter and organize efficiently. Explore the collection at themeajio.com.
Moaffzey is a brand that provides both computer memory modules and educational materials. Their RAM options include DDR3 and DDR4 modules designed for desktops and laptops, supporting different speeds and voltages depending on the configuration. The brand also offers educational posters and charts that cover basic learning topics for young children. Information about Moaffzey products and specifications can be found on the official site https://moaffzey.com. Overall, Moaffzey combines technology-focused components with educational resources in a single product range.
Mojiate is a brand focused on producing equipment for water sports and fishing enthusiasts. Their product range includes fishing rod holders, boat ladders, steering wheels, and folding shower seats, made from materials such as alloy steel, aluminum, and marine-grade stainless steel to withstand outdoor and marine conditions. Mojiate products are designed for durability, corrosion resistance, and practical use in various water-based activities. More information on specifications and product types is available at https://themojiate.com. Overall, Mojiate combines reliable construction with functional designs suitable for both recreational and professional users.
Oddmoal is a brand known for high-quality pens that combine functionality, style, and comfort. Their product lineup includes ballpoint pens with stylus tips, soft-touch click pens, and 2-in-1 metal pens designed for smooth writing and touchscreen compatibility. With medium-point black ink and ergonomic designs, these pens are suitable for both professional and personal use.Oddmoal pens are compatible with a wide range of paper types, offer consistent ink flow, and include features that enhance comfort for long writing sessions. Explore more at https://oddmoal.com and elevate your writing experience with a blend of practicality and elegance.
OwlTree provides several hardware options for PC builders, focusing on connectivity and system management. Their products include fan controllers, USB header splitters, and GPU support brackets that can accommodate different component sizes and configurations. The adapters allow compatibility between various RGB hubs and standard fan devices, simplifying connections in multi-device setups. Information about specifications, supported devices, and installation guidance can be found on the official site: https://owltree-store.com/. Overall, OwlTree components serve as practical solutions for adjusting and expanding PC hardware setups without significant modifications.
https://medium.com/p/a4ea8e21fdde
QUICO provides hair styling devices designed for efficiency and versatility, including hair straighteners, blow dryers, and multi-functional styling brushes. Their products feature fast heating, dual voltage for international use, and negative ion technology to minimize frizz and enhance shine. Accessories such as gloves and clips improve usability and safety during styling. Detailed information on specifications, supported features, and usage tips can be found on the official site: https://thequico.com/. Overall, QUICO tools are intended to simplify styling routines while accommodating different hair types and travel needs.
SOONAN provides high-quality mini pliers and comprehensive electronics tool kits for DIY enthusiasts, professionals, and hobbyists. Their 5-, 8-, and 13-piece mini pliers sets include long nose pliers, diagonal cutters, end cutters, and bent nose nippers, all made from durable stainless steel for long-lasting performance. Each tool is compact, ergonomic, and spring-loaded for precision tasks such as jewelry making, electronics repair, and small household projects.Discover full product specifications, pricing, and availability on the official website: https://thesoonan.com/. SOONAN tools combine precision, durability, and versatility, making them ideal for professional repairs and detailed DIY work.
SUNSHINE FARMRE provides heavy-duty, versatile farm equipment for subcompact tractors like Kubota and John Deere. The 3 Point Trailer Hitch includes multiple trailer ball sizes and a towing hook for light and heavy-duty towing. Made of stainless steel with black powder coating, it resists rust and corrosion. Additional products like upgraded Tractor Bucket Hitches, RV Stabilizer Jacks, Wire Spool Racks, and Playground Handles offer durability, stability, and easy installation. Improve towing efficiency and farm productivity with reliable SUNSHINE FARMRE equipment. Explore more at sunshine-farmre.com.
สล็อต PG เกมสล็อตออนไลน์ที่คนค้นหาเยอะ ใช้งานง่าย ฝากถอนรวดเร็ว
คำค้นหา PG Slot กำลังได้รับความนิยมอย่างต่อเนื่อง ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น แบรนด์เกมที่โดดเด่น ด้าน กราฟิก ความ ลื่นไหล และ โอกาสรับกำไรที่ดี เกมของ PG ออกแบบโดยทีมงานมืออาชีพ ที่รองรับการเล่นทั้งบน มือถือ และ พีซี
ความโดดเด่น ของ PG Slot
pg slot เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ เข้าเกมไว เล่นผ่าน ระบบออนไลน์ และรองรับ ทั้ง iOS และ Android ไม่ต้องติดตั้งเพิ่มเติม ผู้เล่นสามารถเข้าเล่นผ่าน Browser ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ สามมิติ ให้ความคมชัด พร้อมเอฟเฟกต์ จัดเต็ม
คุณสมบัติหลักของเกม PG Slot ได้แก่
ระบบโบนัสและฟรีสปินหลากหลายรูปแบบ
ฟีเจอร์ตัวคูณรางวัล
เล่นฟรีก่อนเติมเงิน
รองรับภาษาไทยเต็มรูปแบบ
ระบบการเงินรวดเร็ว ไม่ต้องรอนาน
แพลตฟอร์ม สล็อต PG โดยทั่วไปให้บริการ การฝาก-ถอน ออโต้ตลอด 24 ชม. ขั้นต่ำเริ่มต้นเพียง 10 บาท ขึ้นอยู่กับ ระบบของผู้ให้บริการ การทำรายการใช้เวลา ไม่กี่วินาที ผ่าน สแกน QR หรือระบบ แอปธนาคาร ทำให้ธุรกรรมเป็นไปอย่าง ไม่สะดุด
แนวเกมที่คนเล่นเยอะ ใน PG Slot
เกม PG Slot มีธีมหลากหลาย เช่น
ธีม เทพเจ้า
ธีม ผจญภัย
ธีม ความมั่งคั่ง
ธีม Animal
หลายคนชอบเกมที่โบนัสเข้าไว พร้อมระบบ Special Feature และ อัตราการจ่ายที่สูง เหมาะกับทั้ง ผู้เล่นเริ่มต้น และ สายสล็อตจริงจัง
ความปลอดภัย
สล็อต PG พัฒนาในระบบสากล มีการ เข้ารหัสข้อมูล และใช้ระบบสุ่มผล ระบบสุ่มมาตรฐาน เพื่อให้ผลลัพธ์ ตรวจสอบได้ แพลตฟอร์มที่ให้บริการ PG Slot ควรมี ระบบดูแลข้อมูล
โดยภาพรวม
สล็อต PG เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน โบนัสหลากหลาย และการทำธุรกรรมที่ ไว ผู้เล่นสามารถเริ่มต้นได้ ไม่ซับซ้อน ฝากถอนสะดวก และเลือกเกมได้ จำนวนมาก เหมาะสำหรับ ทั้งมือใหม่และมือโปร ในโลกของเกมสล็อตออนไลน์
Selecting a suitable container for daily hydration requires evaluating material safety and lid mechanics to prevent accidental spills. Technical specifications for Vikaster items indicate a focus on food-grade plastics and stainless steel, ensuring all components remain BPA-free and odorless. Many of these vessels incorporate silicone sealing rings and safety locks, which are essential for transporting liquids in backpacks or gym bags. It is common to find variations in capacity, ranging from compact 350 ml versions for children to larger 1.5 L models for extended outdoor activities. Maintenance is typically straightforward, as many designs feature wide openings or detachable straws for thorough cleaning. Users often compare these features when looking for alternatives to single-use plastics for school or fitness environments. Detailed lists regarding temperature retention and weight can be found at https://thevikaster.com/ to assist with specific equipment transitions. The Vikaster range serves as a practical example of how modern hydration hardware integrates portable straps and ergonomic grips for active users.
pg slot เกมสล็อตออนไลน์ที่คนค้นหาเยอะ ใช้งานง่าย ฝากถอนรวดเร็ว
คำค้นหา pg slot กำลังได้รับความนิยมอย่างต่อเนื่อง ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น ค่ายเกมที่มีชื่อเสียง ด้าน งานภาพคุณภาพสูง ความ เสถียร และ ระบบจ่ายที่ดึงดูด เกมของ PG พัฒนาโดยผู้ให้บริการชั้นนำ ที่รองรับการเล่นทั้งบน โทรศัพท์มือถือ และ พีซี
ข้อดี ของ สล็อต PG
สล็อต PG เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ เปิดเกมได้ทันที เล่นผ่าน ระบบเว็บ และรองรับ ทุกอุปกรณ์ ไม่ต้องติดตั้งเพิ่มเติม ผู้เล่นสามารถเข้าเล่นผ่าน เว็บเบราว์เซอร์ ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ สามมิติ ให้ความคมชัด พร้อมเอฟเฟกต์ จัดเต็ม
คุณสมบัติหลักของเกม PG Slot ได้แก่
ระบบโบนัสและฟรีสปินหลากหลายรูปแบบ
Multiplier
โหมดทดลองเล่นฟรี
ใช้งานภาษาไทยง่าย
ระบบการเงินรวดเร็ว ไม่ต้องรอนาน
แพลตฟอร์ม pg slot โดยทั่วไปให้บริการ การฝาก-ถอน ฝากถอนตลอดเวลา ขั้นต่ำเริ่มต้นเพียง หลักหน่วย ขึ้นอยู่กับ เงื่อนไขของเว็บไซต์ การทำรายการใช้เวลา เพียงไม่กี่วินาที ผ่าน สแกน QR หรือระบบ ธนาคารบนมือถือ ทำให้ธุรกรรมเป็นไปอย่าง ไม่สะดุด
แนวเกมที่คนเล่นเยอะ ใน PG Slot
เกม pg slot มีธีมหลากหลาย เช่น
ธีม แฟนตาซี
ธีม ผจญภัย
ธีม โชคลาภ
ธีม ธรรมชาติ
ผู้เล่นนิยมเกมที่มีรอบพิเศษบ่อย พร้อมระบบ ฟีเจอร์พิเศษ และ อัตราการจ่ายที่สูง เหมาะกับทั้ง ผู้เล่นเริ่มต้น และ ผู้เล่นมือโปร
มาตรฐานระบบ
สล็อต PG ใช้ระบบที่ได้มาตรฐาน มีการ เข้ารหัสข้อมูล และใช้ระบบสุ่มผล Random Number Generator เพื่อให้ผลลัพธ์ ยุติธรรม แพลตฟอร์มที่ให้บริการ pg slot ควรมี ระบบดูแลข้อมูล
โดยภาพรวม
สล็อต PG เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน กราฟิกคุณภาพ และการทำธุรกรรมที่ รวดเร็ว ผู้เล่นสามารถเริ่มต้นได้ ทันที ฝากถอนสะดวก และเลือกเกมได้ ครบทุกหมวด เหมาะสำหรับ ทุกระดับประสบการณ์ ในโลกของเกมสล็อตออนไลน์
PG
PG Slot แพลตฟอร์มเกมสล็อตยอดนิยม เล่นง่าย ฝากถอนเร็ว
คำค้นหา pg slot กำลังได้รับความนิยมอย่างต่อเนื่อง ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น ค่ายเกมที่มีชื่อเสียง ด้าน กราฟิก ความ เสถียร และ โอกาสรับกำไรที่ดี เกมของ PG ออกแบบโดยทีมงานมืออาชีพ ที่รองรับการเล่นทั้งบน มือถือ และ คอมพิวเตอร์
ข้อดี ของ สล็อต PG
pg slot เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ โหลดเร็ว เล่นผ่าน ระบบอัตโนมัติ และรองรับ ทุกอุปกรณ์ เข้าเล่นผ่านเว็บได้เลย ผู้เล่นสามารถเข้าเล่นผ่าน Browser ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ เอฟเฟกต์ 3 มิติ ให้ความคมชัด พร้อมเอฟเฟกต์ จัดเต็ม
คุณสมบัติหลักของเกม pg slot ได้แก่
โบนัสและฟรีสปินหลายแบบ
ฟีเจอร์ตัวคูณรางวัล
โหมดทดลองเล่นฟรี
ใช้งานภาษาไทยง่าย
ระบบการเงินรวดเร็ว ทำรายการไว
แพลตฟอร์ม สล็อต PG ส่วนใหญ่รองรับ การฝาก-ถอน ออโต้ตลอด 24 ชม. ขั้นต่ำเริ่มต้นเพียง 1 บาท ขึ้นอยู่กับ ระบบของผู้ให้บริการ การทำรายการใช้เวลา ไม่กี่วินาที ผ่าน คิวอาร์โค้ด หรือระบบ ธนาคารบนมือถือ ทำให้ธุรกรรมเป็นไปอย่าง ต่อเนื่อง
ประเภทเกมยอดนิยม ใน pg slot
เกม สล็อต PG มีธีมหลากหลาย เช่น
ธีม เทพเจ้า
ธีม ลุยด่าน
ธีม โชคลาภ
ธีม ธรรมชาติ
ผู้เล่นนิยมเกมที่มีรอบพิเศษบ่อย พร้อมระบบ โบนัสรอบพิเศษ และ โอกาสทำกำไรสูง เหมาะกับทั้ง ผู้เล่นเริ่มต้น และ ผู้เล่นที่มีประสบการณ์
ความน่าเชื่อถือ
pg slot มีมาตรฐานรองรับ มีการ ปกป้องข้อมูลผู้เล่น และใช้ระบบสุ่มผล Random Number Generator เพื่อให้ผลลัพธ์ ตรวจสอบได้ แพลตฟอร์มที่ให้บริการ สล็อต PG ควรมี ความปลอดภัยสูง
บทสรุปท้ายบท
สล็อต PG เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน โบนัสหลากหลาย และการทำธุรกรรมที่ ไว ผู้เล่นสามารถเริ่มต้นได้ ทันที ฝากถอนสะดวก และเลือกเกมได้ หลากหลายแนว เหมาะสำหรับ ทุกระดับประสบการณ์ ในโลกของเกมสล็อตออนไลน์
ทดลองเล่นสล็อต pg
TKBNEKO เปิดประสบการณ์ใหม่แห่งการเดิมพันออนไลน์ ธุรกรรมรวดเร็ว ด้วยระบบสแกน QR Code
ในยุคดิจิทัลที่ เทคโนโลยีพัฒนาอย่างรวดเร็ว เรามุ่งเน้นมาตรฐานใหม่ของการเดิมพัน ด้วยระบบที่ ล้ำสมัย เสถียร และ ตรวจสอบได้ เพื่อให้ผู้เล่น มั่นใจ ทุกครั้งที่ใช้งาน
จุดเด่นระบบฝาก-ถอน
ฝากขั้นต่ำ: 1 บาท
ถอนขั้นต่ำ: ขั้นต่ำ 1 บาท
เวลาฝากเงิน: ภายใน 3 วินาที
ยอดถอน: ไม่จำกัดต่อวัน
ฝากง่าย เพียงสแกน QR Code
สแกน คิวอาร์ ระบบจะ ประมวลผลอัตโนมัติ ขั้นต่ำ 100 บาท สูงสุด 500,000 บาท
หมวดหมู่เกม
สล็อต: ธีมหลากหลาย
เกมสด: คาสิโนเรียลไทม์
กีฬา: แมตช์ทั่วโลก
ยิงปลา: ลุ้นกำไรทันที
โปรโมชั่นและสิทธิพิเศษ
ติดตามหน้า โบนัส พร้อมระบบ VIP และโปรแกรม แอฟฟิลิเอต
ฝ่ายบริการลูกค้า
สอบถามข้อมูลได้ตลอด 24 ชั่วโมง ผ่านหน้า ศูนย์ช่วยเหลือ ทีมงาน TKBNEKO พร้อมดูแลตลอดเวลา
ทดลองเล่นสล็อต pg ซื้อฟรีสปิน
this website
Miracle Alien Cookies
cannabis clones california
White Widow
заказать кухню по индивидуальному заказу заказать кухню по индивидуальному заказу .
мелбет вход с мобильного
Скачать Melbet: Android, iPhone и компьютер
Приложение Melbet включает букмекерскую контору и казино в едином приложении. Пользователю доступны live-ставки, слоты, онлайн-трансляции, аналитика и операции по счёту. Установка занимает несколько минут.
Android (APK)
Загрузите APK с официального источника, откройте файл и завершите установку. При необходимости включите доступ к установке сторонних приложений, затем войдите в аккаунт.
iOS (iPhone)
Откройте App Store, найдите «Melbet», нажмите «Получить», после установки выполните вход.
ПК
Откройте официальный сайт, авторизуйтесь и добавьте ярлык на рабочий стол. Браузерная версия функционирует как отдельное приложение.
Функционал
Live-ставки с обновлением коэффициентов, казино и слоты, прямые трансляции, подробная статистика, push-оповещения, регистрация за минуту и круглосуточная служба поддержки.
Бонусы
После установки доступны бонус на первый депозит, промокоды и бесплатные ставки. Условия зависят от региона.
Безопасность
Скачивайте только с официальных источников, контролируйте адрес сайта, не передавайте пароль третьим лицам и включите 2FA.
Загрузка выполняется быстро, после чего доступен весь функционал Melbet.
melbet casino
Установить Melbet: Android, iPhone и компьютер
Мобильная версия Melbet включает ставки и казино в одном интерфейсе. Доступны live-ставки, слоты, онлайн-трансляции, статистика и операции по счёту. Загрузка занимает несколько минут.
Android (APK)
Скачайте APK с официального источника, откройте файл и завершите установку. При необходимости включите доступ к установке сторонних приложений, затем войдите в аккаунт.
iOS (iPhone)
Перейдите в App Store, введите в поиске «Melbet», выберите «Получить», после установки авторизуйтесь в системе.
ПК
Перейдите официальный сайт, войдите в личный кабинет и создайте ярлык на рабочий стол. Веб-версия работает как полноценное приложение.
Функционал
Live-ставки с обновлением коэффициентов, казино и слоты, просмотр матчей, подробная статистика, push-оповещения, регистрация за минуту и круглосуточная служба поддержки.
Бонусы
После загрузки доступны приветственный бонус, промокоды и фрибеты. Правила начисления определяются регионом.
Безопасность
Загружайте только с официальных источников, проверяйте домен, не передавайте пароль третьим лицам и включите 2FA.
Установка занимает несколько минут, после чего открывается полный доступ Melbet.
заказать кухню под размеры заказать кухню под размеры .
ทดลองเล่นสล็อต pg ซื้อฟรีสปิน
мелбет приложение для ios
Установить приложение Melbet: APK, iOS и компьютер
Приложение Melbet включает ставки и казино в едином приложении. Пользователю доступны live-ставки, казино-игры, онлайн-трансляции, аналитика и операции по счёту. Установка занимает 1–2 минуты.
Android (APK)
Загрузите APK с официального сайта, запустите установщик и завершите установку. При необходимости включите разрешение на установку из неизвестных источников, затем авторизуйтесь.
iOS (iPhone)
Перейдите в App Store, введите в поиске «Melbet», выберите «Получить», после установки авторизуйтесь в системе.
ПК
Перейдите официальный сайт, войдите в личный кабинет и создайте ярлык на рабочий стол. Веб-версия работает как отдельное приложение.
Функционал
Live-ставки с обновлением коэффициентов, игровой раздел с тысячами игр, просмотр матчей, аналитические данные, уведомления о матчах, быстрая регистрация и поддержка 24/7.
Бонусы
После загрузки доступны бонус на первый депозит, промокоды и бесплатные ставки. Правила начисления определяются регионом.
Безопасность
Скачивайте только с официальных источников, проверяйте домен, не сообщайте данные доступа третьим лицам и активируйте двухфакторную аутентификацию.
Загрузка выполняется быстро, после чего доступен весь функционал Melbet.
заказать проект перепланировки квартиры в москве teletype.in/@jorik11/proekt-dlya-pereplanirovki .
1win timp de retragere https://1win5805.help
кухни на заказ санкт петербург kuhni-spb-41.ru .
кухню заказать кухню заказать .
кухни под заказ kuhni-spb-41.ru .
кухни на заказ от производителя kuhni-spb-41.ru .
внедрение erp стоимость 1с внедрение erp стоимость 1с .
I came across https://abhayywigs.com/ while looking for a lace front wig with a soft wave pattern. The texture feels natural, and the lace blended better than I expected. It’s comfortable enough to wear all day, which was important to me.
After browsing https://shopairsong.com/, I decided to try one of their minimizer styles. The fit felt balanced — secure without being overly compressive. It smooths things out under clothes while still feeling breathable.
I found https://andriawigs.com/ while searching for a new wig style. The lace front looks natural, and the hair density feels balanced. Out of curiosity, I also tried their gourmet sauce — it has a smooth texture and just the right amount of kick. Definitely a unique shopping experience.
I ended up ordering from https://angryramshoes.com/ after reading through reviews. The boots feel stable, the steel toe doesn’t pinch, and the sole grip is solid. It’s a straightforward choice that fits into daily routine without much thought.
I found https://shopaquamiracle.com/ while comparing air pumps. The descriptions were clear, and reviews helped narrow things down. After switching, oxygen flow feels more even, and my fish seem more active. It’s subtle, but noticeable if you spend time watching your tank.
The structure feels sturdy and looks beautiful in photos. Setup was straightforward and didn’t take much time. It worked perfectly as a focal point for the celebration. https://aseem-arch.com/ delivered a backdrop that feels both stylish and reliable.
After checking https://baicaigifts.com/, I picked a curated gift basket for a friend. It arrived neatly packaged and looked just like the photos. The whole experience felt easy and thoughtful.
I ended up ordering from https://thebalency.com/ and was pleasantly surprised by the quality. The belt feels secure, and the materials seem built to last. It’s become a regular part of leg day without overcomplicating things.
I ended up ordering from https://thebattop.com/ and was pleasantly surprised. The pregnancy pillow feels sturdy yet soft, and it holds its shape well. It’s one of those practical purchases that quietly improves everyday comfort.
I came across https://thebeyondheat.com/ while looking for a compact electric heater with adjustable settings. It warms the space surprisingly quickly, and the thermostat makes it easy to keep a steady temperature. It’s simple, but it changed how usable the space feels.
After browsing https://blakeandlake.com/, I ordered a keepsake box for letters and small souvenirs. The craftsmanship feels thoughtful, and the finish highlights the grain nicely. It’s not flashy — just quietly elegant.
I found https://theblyhair.com/ while looking for something simple but interactive. The couple game we tried sparked conversations we hadn’t had in a while. It felt easy and natural, not forced or cheesy.
I just needed better-looking tail lights and found https://theboine.com/ during my search. The whole process was straightforward. After installing them, the back end of the truck looked refreshed without overdoing it. It feels like a subtle but noticeable improvement.
After browsing https://boorosappliance.com/, I ordered one of their dough mixers. It handles thicker dough better than I expected and feels sturdy on the counter. It’s made weekend baking a lot more enjoyable.
I found https://brave-person.com/ while comparing swim briefs. The fit feels snug without being tight, and the material dries quickly. It works well for both swimming laps and relaxing at the pool.
After checking https://thecastamere.com/, I picked up a pair for a special occasion. They fit true to size and feel balanced when walking. It’s subtle, but they definitely made me stand a little taller.
I recently picked up a mic from https://thecoconise.com/ and honestly didn’t expect such a difference in sound quality. My teammates immediately said my voice sounded clearer and more balanced. The one-touch mute is super convenient, and the RGB lighting adds a nice touch to my desk without being distracting.
I picked up a mouse pad and a shower curtain from https://thecolorfulstar.com/ and I’m really enjoying them. The colors are lively, the quality is solid, and it makes my home feel more cheerful overall.
I recently picked up a CONODO Bluetooth MP3 player from https://conodoplayers.com/ and it’s been great for my workouts and walks. The HiFi sound quality is impressive for such a compact device, and pairing with my headphones was effortless.
I found https://thecoolfor.com/ while looking for a small ceramic heater for my desk area. It heats up quickly without being loud, which surprised me. Now I turn it on while making coffee, and the room feels comfortable within minutes.
Coqin’s toys from https://thecoqin.com/ are just perfect. My infant enjoys the gentle music and different textures, and I feel confident knowing it’s safe and high-quality.
We’ve been using Coral Isles sunscreen from https://coral-isles.com/ for a couple of weeks. It spreads easily, is water-resistant, and the kids didn’t fuss about reapplying. I like that it’s reef-safe too, so we can enjoy the ocean without worrying about the environment.
Installed a CREWEEL motion sensor night light from https://creweel.com/ in our hallway, and it works perfectly. It lights up only when needed, dimmable to avoid harsh glare, and no more fumbling in the dark.
After spending time on https://cute-castle.com/, I decided to try their swaddles and cloths. The material feels gentle and breathable, and everything arrived exactly as described. It’s comforting to find basics that feel well made without overcomplicating things.
I picked up some face gems and a small LED garland from https://danhh.com/ to decorate for a mini party, and it turned out so fun. Everything was easy to use, bright, and added a playful touch.
I got a D.DUO purse organizer from https://d-duo.com/ and it’s perfect for keeping my bags neat. The multiple compartments fit everything I carry daily, and it feels durable while still looking chic. It has made my daily commute and errands so much smoother.
I recently tried a pack of DEEP TOUCH boyshorts from https://shopdeeptouch.com/, and they’re incredible. The fabric feels soft and breathable, and I barely notice them under my clothes. Perfect for workdays or lounging at home, they’re comfortable enough to wear all day without adjusting.
I got a 16-inch Devonia lace front wig from https://devoniawigs.com/ and it’s quickly become my go-to for work and casual outings. The waves are bouncy and hold well, plus it feels lightweight and breathable. Definitely exceeded my expectations for a human hair wig.
I found https://thediandian.com/ and decided to try one of their rack cases. It’s solid, keeps everything in place, and feels watertight. Now I can focus on the set instead of my gear, which is a huge relief.
I ordered a few Do²ping foam sheets from https://do2ping.com/ for a cosplay build. They’re lightweight, easy to manipulate, and the quality is consistent. Working on my costume has been so much smoother with these sheets.
I added a tactical folding knife from https://doom-blade.com/ to my gear, and it’s been super handy. Sharp, durable, and easy to carry, it handles small tasks around camp effortlessly. It’s the kind of knife that just feels right in your hand.
I tried DUFU’s no-drill racks and holders from https://thedufu.com/ and was pleasantly surprised. They look sleek, don’t damage walls, and make finding what I need so much easier.
I ended up browsing https://shopeboot.com/ while looking for simple cable clips. Nothing fancy — just something that would keep chargers from sliding off the table. They were easy to place, hold well, and now my workspace feels calmer. It’s a small fix, but it makes daily work smoother.
I ordered an initial necklace from https://endless-story-jewelry.com/ for my best friend and it arrived quickly. The quality is excellent, and the personal touch made it feel much more meaningful than a generic piece of jewelry.
Weekends are when I want comfort without looking like I gave up. I’ll reach for my https://faironlydress.com/ and not think about it again. It moves easily and doesn’t need constant fixing. I can sit, walk, or stay out longer than planned. By the end of the day, I’m still glad I chose it.
I wear my joggers at home and when I head out briefly. They move well without feeling loose. Comfort matters to me more than style trends. https://thefirstgym.com/ delivers joggers that match that mindset.
I started carrying a portable bidet after a few long days away from home. It helped me feel clean when restrooms felt rushed or uncomfortable. I noticed less irritation and more ease during the day. For me, that small change made daily routines feel steadier with https://foofooshop.com/.
But after ordering from https://thefunhot.com/, I was surprised how manageable it felt. The balloons inflated evenly, and the arrangement guide helped a lot. It turned into a fun part of the preparation instead of a chore.
I picked up a set of stair riser decals from https://funlifestore.com/ last week. Applying them was simple and way less messy than I expected. The staircase instantly feels more lively. Walking up and down has become kind of fun now.
I helped my daughter pick her dress today. https://thegalluria.com/ was printed on the tag, but she didn’t notice. She twirled around the room while getting ready. The dress made her move freely without any fuss.
Transportation and daily mobility used to be stressful, but the https://thegoldseason.com/ chair is compact, folds easily, and rolls smoothly indoors and outdoors. It’s made simple tasks feel much more manageable and gives a real sense of independence.
I used an adjustable podium from https://thegsow.com/ during a presentation. The height adjustment felt effortless. Attendees could see the speaker clearly from every angle. The setup didn’t take more than a few minutes.
Every evening I place my watches back in their box. The soft compartments prevent scratches and misplacement. It gives me peace of mind knowing they are safe. https://theguka.com/ designed it to balance protection with style seamlessly.
I find it easier to keep my products clean and separated. The interior layout supports frequent use. It works well both at home and while traveling. https://thehaisky.com/ delivers consistency in everyday organization.
I came across Halfword while scrolling for outfit ideas and decided to try a two-piece set from https://thehalfword.com/. It’s stylish but still comfortable, which is rare. I’ve already worn it twice — once casually and once dressed up with heels.
We tried Hanani for winter shoes and kids’ cleats, and both worked great. The boots are cozy and durable, and the cleats are light and easy to run in. https://thehanani.com/ has definitely made footwear shopping stress-free.
I started using their scoopers and feeders from https://thehumumu.com/ last week. Everything is lightweight and easy to store. My mornings are faster and more organized. The chickens seem to enjoy the new layout too.
melbet официальный сайт скачать на ios
Установить Melbet: APK, iOS и ПК
Приложение Melbet объединяет ставки и казино в едином приложении. Доступны live-ставки, слоты, онлайн-трансляции, аналитика и операции по счёту. Загрузка занимает несколько минут.
Android (APK)
Скачайте APK с официального сайта, запустите установщик и завершите установку. При необходимости включите доступ к установке сторонних приложений, затем войдите в аккаунт.
iOS (iPhone)
Откройте App Store, найдите «Melbet», выберите «Получить», после установки выполните вход.
ПК
Откройте официальный сайт, войдите в личный кабинет и создайте ярлык на рабочий стол. Веб-версия работает как отдельное приложение.
Функционал
Live-ставки с мгновенным обновлением линии, казино и слоты, просмотр матчей, аналитические данные, уведомления о матчах, быстрая регистрация и круглосуточная служба поддержки.
Бонусы
После установки доступны приветственный бонус, акционные коды и фрибеты. Условия зависят от региона.
Безопасность
Загружайте только с официальных источников, проверяйте домен, не передавайте пароль третьим лицам и активируйте двухфакторную аутентификацию.
Загрузка выполняется быстро, после чего открывается полный доступ Melbet.
The lamp provides excellent illumination for reading and working. I appreciate its stable base and smooth operation. It adds a modern touch to my bedroom décor. https://hwdfei.com/ delivers both quality and elegance in one product.
скачать мелбет на android
Установить Melbet: APK, iPhone и ПК
Приложение Melbet объединяет ставки и казино в одном интерфейсе. Доступны live-ставки, слоты, прямые трансляции, статистика и быстрые финансовые операции. Загрузка занимает 1–2 минуты.
Android (APK)
Загрузите APK с официального сайта, откройте файл и подтвердите установку. При необходимости включите разрешение на установку из неизвестных источников, затем войдите в аккаунт.
iOS (iPhone)
Перейдите в App Store, введите в поиске «Melbet», нажмите «Получить», после установки авторизуйтесь в системе.
ПК
Перейдите официальный сайт, авторизуйтесь и создайте ярлык на рабочий стол. Веб-версия работает как полноценное приложение.
Функционал
Live-ставки с мгновенным обновлением линии, казино и слоты, просмотр матчей, аналитические данные, push-оповещения, быстрая регистрация и круглосуточная служба поддержки.
Бонусы
После загрузки доступны бонус на первый депозит, акционные коды и бесплатные ставки. Правила начисления определяются регионом.
Безопасность
Загружайте только с официального сайта, контролируйте адрес сайта, не передавайте пароль третьим лицам и включите 2FA.
Установка занимает несколько минут, после чего доступен весь функционал Melbet.
I picked up the toy before our afternoon session. https://shopiflove.com/ caught my eye on the packaging. We spent time figuring out how each part worked. The room felt alive with curiosity and quiet focus.
I didn’t expect setting up an iRV Technologies stereo would be this smooth. https://irv-technologies.com/ made it easy to get my RV audio system running, and the sound quality is excellent—everything from podcasts to music comes through clear and rich.
I always love having candles around, but real flames make me nervous.
With https://izancandles.com/, I can enjoy the same warm glow without worrying.
I place them near my books or on the shelf, and they feel safe.
I started using a hair curler during slower mornings at home. It helped me feel more put together before stepping out. I liked how the process felt calm rather than rushed. That routine slowly became part of my day with https://thejanelove.com/.
I keep my jewelry on even when the day feels slow. https://thejiangxin.com/ appears once on the tag. The weight feels steady while I move around. By evening, it feels like part of me.
I was pleasantly surprised by the depth and warmth of the sound. The keys respond effortlessly, making long practice sessions comfortable and enjoyable. The craftsmanship of the https://thekayata.com/ saxophone feels reliable and professional. It truly inspires me to practice more every day.
It’s easy to adjust the angle whenever I need a better view. The surface holds all pieces without slipping. I can leave a puzzle unfinished and return later without disruption. https://thelavievert.com/ designed a table that feels both practical and reliable.
After browsing https://theleevan.com/, I ordered a kitchen rug with a subtle pattern. It adds a bit of style to the space while still being easy to clean. The non-slip backing actually works, which is reassuring.
The magnets work perfectly every time. It glides smoothly and seals automatically after passing through. Fresh air comes in without a single mosquito sneaking through. https://theliamst.com/ offers a practical and reliable solution for home comfort.
My eyes feel comfortable even after hours of wear. The shades are perfect for work or going out. It blends beautifully and looks professional. https://mylilybyred.com/ makes me confident in my makeup.
I wasn’t sure a recliner could feel this good, but the one from https://lintingchairs.com/ really hits the mark. The padding is generous, the leather/fabric is soft yet durable, and the built-in massage feature is a real treat after work. It makes relaxing effortless.
I used to think ceiling lights had to be a project. Wires, drilling, all of that. Then I tried https://loleds.com/ and realized it doesn’t have to be dramatic. I mounted it, charged it, and that was basically it. Now I just enjoy having light where I need it. No big story behind it.
The material adapts well to movement and stays in place. It feels neither too heavy nor too light. Care and maintenance are straightforward. https://themapleandstone.com/ blends comfort with practicality in daily use.
After checking https://mars-explo.com/, I added a patio heater and a simple storage cart. Both feel practical and well-made. It didn’t transform everything overnight, but it definitely made the space more functional.
The https://themaxmat.com/ mats worked better than expected. Dirt brushes off easily, water beads right up, and they don’t slide around. It feels like the floors are finally protected without extra effort.
I grabbed a reading pillow from https://themittagong.com/ last month. Sitting up in bed feels much easier now. The neck support is adjustable and feels natural. I find myself reading longer without discomfort.
I ended up ordering from https://modern-memory.com/ out of curiosity, and I was honestly impressed. The scent feels balanced, not overpowering, and it actually lasts through the day. I’ve already gotten a few compliments, which never hurts.
The jacket sits neatly across the shoulders and moves naturally. The trousers maintain a clean line without feeling restrictive. It works well for formal meetings and evening events alike. https://moncace.com/ delivers a fit that feels sharp yet comfortable throughout the day.
During long welding projects, slipping pipes caused frustration and mistakes. The Plier Clamp changed that instantly. It grips firmly without damaging the material. https://monsterandmaster.com/ created a tool that makes my work smoother and stress-free.
After browsing https://mymten.com/, I ordered a paddle set and a net for the driveway. Setup was quick, and everything felt sturdier than I expected. It made starting out way less intimidating. Now we just grab the paddles and play without fuss.
I wanted privacy fast, so velcro curtains felt like the right call. The fabric stays in place through daily movement. Cleaning takes minutes, which keeps things simple. https://mymuamar.com/ blends into my space without demanding attention.
I often ignored the smell rising from my workspace. After trying a fume extractor, I noticed how much cleaner and safer the air became. Long projects felt less exhausting, and small irritations disappeared. https://themuin.com/ worked silently in the background, letting me focus fully on my craft.
I recently ordered a marble tray from https://mulwrmarble.com/ and didn’t expect it to change the feel of my bathroom so much. It’s simple, but the natural marble looks beautiful and feels solid. Now my soap and small items look organized instead of scattered. It’s a small detail that makes the space feel calmer.
нарколог на дом срочно ростов-на-дону нарколог на дом срочно ростов-на-дону .
After spending some time on https://ny-threads.com/, I picked up a robe and a couple of essentials. The materials feel soft but durable, and the sizing was straightforward. It’s simple, practical clothing that fits easily into daily life.
I always carry my https://shopocase.com/ wherever I go. It keeps my cards in order and cash safe. Losing things stresses me out, so this little case helps. I feel more organized each day because of it.
I recently used an OPQRST system from https://opqrstmicrophone.com/ at a live event, and the sound quality blew me away. Setup was straightforward, the range was excellent, and the monitors were crystal clear. It made managing multiple performers so much easier.
I found https://thepakasept.com/ while searching for compact storage solutions. The materials feel solid, and everything was straightforward to set up. Now my shelves feel more balanced instead of chaotic.
ทดลองเล่นสล็อต pg
แพลตฟอร์ม TKBNEKO เปิดประสบการณ์ใหม่แห่งการเดิมพันออนไลน์ ฝาก-ถอนไว ด้วยระบบสแกน QR Code
ในยุคดิจิทัลที่ โลกออนไลน์เติบโตต่อเนื่อง เรามุ่งเน้นมาตรฐานใหม่ของการเดิมพัน ด้วยระบบที่ ทันสมัย เสถียร และ ตรวจสอบได้ เพื่อให้ผู้เล่น อุ่นใจ ทุกครั้งที่ใช้งาน
ระบบการเงินที่ใช้งานง่าย
ฝากขั้นต่ำ: เริ่มต้น 1 บาท
ถอนขั้นต่ำ: 1 บาท
เวลาฝากเงิน: ภายใน 3 วินาที
ยอดถอน: ไม่จำกัดต่อวัน
ฝากง่าย เพียงสแกน QR Code
สแกน QR Code ระบบจะ โอนเงินเข้าทันที ขั้นต่ำ เริ่ม 100 บาท สูงสุด 500,000 บาท
หมวดหมู่เกม
สล็อต: ลุ้นแจ็คพอต
เกมสด: ดีลเลอร์สด
กีฬา: เดิมพันลีกดัง
ยิงปลา: ลุ้นกำไรทันที
โปรโมชั่นและสิทธิพิเศษ
ติดตามหน้า โปรโมชั่น พร้อมระบบ VIP และโปรแกรม แอฟฟิลิเอต
ฝ่ายบริการลูกค้า
สอบถามข้อมูลได้ตลอด 24 ชั่วโมง ผ่านหน้า ศูนย์ช่วยเหลือ ทีมงาน TKBNEKO พร้อมดูแลตลอดเวลา
I chose the men tracksuit for a slow weekend morning. https://thepasok.com/ was printed along the side seam. The fit felt steady while I moved around the house. I ended up wearing it for most of the day.
cannabis clones florida
PG Slot สล็อตยอดฮิต เข้าเล่นไว ฝากถอนออโต้
คำค้นหา สล็อต PG กำลังได้รับความนิยมอย่างต่อเนื่อง ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น ค่ายเกมที่มีชื่อเสียง ด้าน งานภาพคุณภาพสูง ความ ลื่นไหล และ อัตราการจ่ายรางวัลที่น่าสนใจ เกมของ PG ผลิตโดยค่ายมาตรฐาน ที่รองรับการเล่นทั้งบน สมาร์ทโฟน และ เดสก์ท็อป
ความโดดเด่น ของ pg slot
pg slot เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ เปิดเกมได้ทันที เล่นผ่าน ระบบเว็บ และรองรับ ทุกอุปกรณ์ ไม่ต้องติดตั้งเพิ่มเติม ผู้เล่นสามารถเข้าเล่นผ่าน Browser ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ เอฟเฟกต์ 3 มิติ ให้ความคมชัด พร้อมเอฟเฟกต์ สมจริง
คุณสมบัติหลักของเกม pg slot ได้แก่
โบนัสและฟรีสปินหลายแบบ
ฟีเจอร์ตัวคูณรางวัล
เล่นฟรีก่อนเติมเงิน
ใช้งานภาษาไทยง่าย
ระบบการเงินรวดเร็ว ไม่ต้องรอนาน
แพลตฟอร์ม PG Slot โดยทั่วไปให้บริการ การฝาก-ถอน ฝากถอนตลอดเวลา ขั้นต่ำเริ่มต้นเพียง 1 บาท ขึ้นอยู่กับ ระบบของผู้ให้บริการ การทำรายการใช้เวลา เพียงไม่กี่วินาที ผ่าน คิวอาร์โค้ด หรือระบบ ธนาคารบนมือถือ ทำให้ธุรกรรมเป็นไปอย่าง ต่อเนื่อง
หมวดเกมฮิต ใน pg slot
เกม สล็อต PG มีธีมหลากหลาย เช่น
ธีม แฟนตาซี
ธีม ลุยด่าน
ธีม ความมั่งคั่ง
ธีม ธรรมชาติ
ผู้เล่นนิยมเกมที่มีรอบพิเศษบ่อย พร้อมระบบ โบนัสรอบพิเศษ และ โอกาสทำกำไรสูง เหมาะกับทั้ง คนเพิ่งเล่น และ ผู้เล่นที่มีประสบการณ์
มาตรฐานระบบ
pg slot พัฒนาในระบบสากล มีการ เข้ารหัสข้อมูล และใช้ระบบสุ่มผล ระบบสุ่มมาตรฐาน เพื่อให้ผลลัพธ์ ยุติธรรม แพลตฟอร์มที่ให้บริการ pg slot ควรมี ทีมซัพพอร์ต 24 ชม.
โดยภาพรวม
pg slot เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน กราฟิกคุณภาพ และการทำธุรกรรมที่ ไว ผู้เล่นสามารถเริ่มต้นได้ ไม่ซับซ้อน ฝากถอนสะดวก และเลือกเกมได้ ครบทุกหมวด เหมาะสำหรับ ทั้งมือใหม่และมือโปร ในโลกของเกมสล็อตออนไลน์
ทดลองเล่นสล็อต pg เว็บ ตรง”
สล็อต PG เกมสล็อตออนไลน์ที่คนค้นหาเยอะ ใช้งานง่าย ฝากถอนรวดเร็ว
คำค้นหา pg slot มาแรงในช่วงนี้ ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น แบรนด์เกมที่โดดเด่น ด้าน งานภาพคุณภาพสูง ความ เสถียร และ โอกาสรับกำไรที่ดี เกมของ PG ออกแบบโดยทีมงานมืออาชีพ ที่รองรับการเล่นทั้งบน สมาร์ทโฟน และ พีซี
ข้อดี ของ สล็อต PG
PG Slot เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ เข้าเกมไว เล่นผ่าน ระบบเว็บ และรองรับ ทั้ง iOS และ Android ไม่ต้องดาวน์โหลดแอป ผู้เล่นสามารถเข้าเล่นผ่าน Browser ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ เอฟเฟกต์ 3 มิติ ให้ความคมชัด พร้อมเอฟเฟกต์ สมจริง
คุณสมบัติหลักของเกม pg slot ได้แก่
มีรอบโบนัสให้ลุ้นบ่อย
ฟีเจอร์ตัวคูณรางวัล
เล่นฟรีก่อนเติมเงิน
ใช้งานภาษาไทยง่าย
ระบบฝากถอนสะดวก ไม่ต้องรอนาน
แพลตฟอร์ม สล็อต PG มักมี การฝาก-ถอน อัตโนมัติ 24 ชั่วโมง ขั้นต่ำเริ่มต้นเพียง 10 บาท ขึ้นอยู่กับ ระบบของผู้ให้บริการ การทำรายการใช้เวลา ไม่กี่วินาที ผ่าน คิวอาร์โค้ด หรือระบบ แอปธนาคาร ทำให้ธุรกรรมเป็นไปอย่าง ต่อเนื่อง
หมวดเกมฮิต ใน pg slot
เกม สล็อต PG มีธีมหลากหลาย เช่น
ธีม เทพเจ้าและแฟนตาซี
ธีม Adventure
ธีม ความมั่งคั่ง
ธีม ธรรมชาติ
ผู้เล่นนิยมเกมที่มีรอบพิเศษบ่อย พร้อมระบบ ฟีเจอร์พิเศษ และ ระบบจ่ายคุ้มค่า เหมาะกับทั้ง ผู้เล่นเริ่มต้น และ ผู้เล่นที่มีประสบการณ์
มาตรฐานระบบ
สล็อต PG มีมาตรฐานรองรับ มีการ เข้ารหัสข้อมูล และใช้ระบบสุ่มผล Random Number Generator เพื่อให้ผลลัพธ์ โปร่งใส แพลตฟอร์มที่ให้บริการ PG Slot ควรมี ทีมซัพพอร์ต 24 ชม.
สรุป
pg slot เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน กราฟิกคุณภาพ และการทำธุรกรรมที่ ทันใจ ผู้เล่นสามารถเริ่มต้นได้ ทันที ฝากถอนสะดวก และเลือกเกมได้ หลากหลายแนว เหมาะสำหรับ ผู้เล่นทุกสไตล์ ในโลกของเกมสล็อตออนไลน์
แพลตฟอร์ม TKBNEKO พาคุณสู่โลกใหม่ของเกมเดิมพันออนไลน์ ธุรกรรมฉับไว ด้วยระบบสแกน คิวอาร์โค้ด
ในยุคที่ นวัตกรรมดิจิทัลเข้ามาปรับโฉมวงการเกมออนไลน์ TKBNEKO พร้อมยกระดับมาตรฐานการเดิมพัน ด้วยระบบการให้บริการที่ ทันสมัย รวดเร็ว และ โปร่งใส พร้อมต้อนรับสมาชิกทุกท่านสู่ มิติใหม่แห่งความสนุก ที่ เปิดโอกาสให้ทุกคนสร้างรายได้
ทำไมต้อง TKBNEKO?
TKBNEKO มุ่งมั่นที่จะมอบประสบการณ์จากเกมลิขสิทธิ์แท้ โดยเฉพาะเกมที่ ผ่านการรับรองจากสถาบันที่น่าเชื่อถือ และ ได้มาตรฐานสากล เพื่อให้ผู้เล่นทุกคน สบายใจ ได้ว่า จะได้รับความเพลิดเพลินกับเกมที่ ยุติธรรม ข้อมูลไม่รั่วไหล และ มีคุณภาพสูง
ระบบการเงินที่เหนือกว่า
เรามุ่งเน้นความสะดวกของผู้เล่น เพื่อให้คุณ โฟกัสกับความสนุกได้อย่างเต็มที่
ฝากขั้นต่ำ: ขั้นต่ำแค่ 1 บาท
ถอนขั้นต่ำ: ขั้นต่ำ 1 บาท
เวลาฝากเงิน: รวดเร็วทันใจใน 3 วินาที
ยอดจำกัดการถอน: ถอนได้ไม่จำกัดยอด
เติมเงินง่ายด้วย QR Code
เพียงคุณสแกน QR Code ระบบของเราจะ โอนเงินเข้าระบบทันที ขั้นต่ำเพียง อย่างน้อย 100 บาท และสามารถฝากได้สูงถึง 500,000 บาท มาร่วมสนุกกันได้แล้ววันนี้ กับ แพลตฟอร์มของเรา ที่ ใช้งานง่าย ทำกำไรได้รวดเร็ว
เกมยอดนิยมรวมไว้ในที่เดียว
แพลตฟอร์มของเราครอบคลุมทุกแนวเกม รองรับทุกความชอบของผู้เล่น
สล็อต: หลากหลายธีม แจ็คพอตรอคุณอยู่
เกมสด: สัมผัสประสบการณ์คาสิโนแบบเรียลไทม์
กีฬา: รองรับลีกดังระดับโลก
ยิงปลา: สนุกกับการยิงปลาแบบได้เงิน
อัปเดตโปรโมชันล่าสุด
อย่าลืมแวะมาเยี่ยมชมที่หน้า โปรโมชั่น เพื่อรับ โบนัสสุดคุ้ม ที่เรามอบให้สมาชิกทุกท่าน นอกจากนี้ยังมีระบบ ลูกค้าระดับพรีเมียม สำหรับลูกค้าคนสำคัญ และช่องทาง พันธมิตร สำหรับผู้ที่สนใจสร้างรายได้ร่วมกับเรา
ฝ่ายบริการลูกค้า
หากมี คำถาม หรือ ความคิดเห็น สามารถติดต่อทีมงานของเราได้ตลอด 24 ชั่วโมงที่หน้า ศูนย์ช่วยเหลือ และ แบบฟอร์มติดต่อ ทีมงาน TKBNEKO ยินดีให้บริการทุกท่านด้วยใจ
After browsing https://passuspower.com/, I ordered one of their power strips with an extension cord. The spacing between outlets is practical, so plugs aren’t fighting for space. Everything feels secure, and I don’t have to constantly rearrange chargers anymore.
สล็อต
แพลตฟอร์ม TKBNEKO มอบมิติใหม่ของเกมออนไลน์ ธุรกรรมรวดเร็ว ด้วยระบบสแกน QR Code
ในยุคดิจิทัลที่ เทคโนโลยีพัฒนาอย่างรวดเร็ว TKBNEKO พร้อมยกระดับการให้บริการ ด้วยระบบที่ ล้ำสมัย รวดเร็ว และ ตรวจสอบได้ เพื่อให้ผู้เล่น มั่นใจ ทุกครั้งที่ใช้งาน
จุดเด่นระบบฝาก-ถอน
ฝากขั้นต่ำ: 1 บาท
ถอนขั้นต่ำ: 1 บาท
เวลาฝากเงิน: ภายใน 3 วินาที
ยอดถอน: ไม่จำกัดต่อวัน
ฝากง่าย เพียงสแกน QR Code
สแกน คิวอาร์ ระบบจะ โอนเงินเข้าทันที ขั้นต่ำ เริ่ม 100 บาท สูงสุด 500,000 บาท
เกมยอดนิยม
สล็อต: ธีมหลากหลาย
เกมสด: คาสิโนเรียลไทม์
กีฬา: เดิมพันลีกดัง
ยิงปลา: สนุกได้เงินจริง
โปรโมชั่นและสิทธิพิเศษ
ติดตามหน้า โปรโมชั่น พร้อมระบบ VIP และโปรแกรม พันธมิตร
ติดต่อเรา
สอบถามข้อมูลได้ตลอด 24 ชั่วโมง ผ่านหน้า ติดต่อเรา ทีมงาน TKBNEKO พร้อมดูแลตลอดเวลา
After checking https://permolights.com/, I ordered a pair of sconces for the hallway. They mounted securely, and the materials feel durable. Now the space looks more finished, especially in the evenings when the warm light turns on.
สล็อต
TKBNEKO มอบมิติใหม่ของเกมออนไลน์ ฝาก-ถอนไว ด้วยระบบสแกน คิวอาร์โค้ด
ในยุคดิจิทัลที่ โลกออนไลน์เติบโตต่อเนื่อง เรามุ่งเน้นมาตรฐานใหม่ของการเดิมพัน ด้วยระบบที่ ล้ำสมัย เสถียร และ โปร่งใส เพื่อให้ผู้เล่น อุ่นใจ ทุกครั้งที่ใช้งาน
ระบบการเงินที่ใช้งานง่าย
ฝากขั้นต่ำ: 1 บาท
ถอนขั้นต่ำ: 1 บาท
เวลาฝากเงิน: ใช้เวลาเพียง 3 วินาที
ยอดถอน: ไม่มีลิมิต
เติมเงินง่าย แค่สแกน
สแกน คิวอาร์ ระบบจะ โอนเงินเข้าทันที ขั้นต่ำ เริ่ม 100 บาท สูงสุด ไม่เกิน 500,000 บาทต่อครั้ง
หมวดหมู่เกม
สล็อต: ลุ้นแจ็คพอต
เกมสด: ดีลเลอร์สด
กีฬา: เดิมพันลีกดัง
ยิงปลา: สนุกได้เงินจริง
โบนัสและโปรโมชัน
ติดตามหน้า โบนัส พร้อมระบบ VIP และโปรแกรม พันธมิตร
ติดต่อเรา
สอบถามข้อมูลได้ตลอด 24 ชั่วโมง ผ่านหน้า ติดต่อเรา ทีมงาน ของเรา พร้อมดูแลตลอดเวลา
pg slot เกมสล็อตออนไลน์ที่คนค้นหาเยอะ ใช้งานง่าย ฝากถอนรวดเร็ว
คำค้นหา สล็อต PG มาแรงในช่วงนี้ ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น ค่ายเกมที่มีชื่อเสียง ด้าน งานภาพคุณภาพสูง ความ นิ่งไม่สะดุด และ อัตราการจ่ายรางวัลที่น่าสนใจ เกมของ PG พัฒนาโดยผู้ให้บริการชั้นนำ ที่รองรับการเล่นทั้งบน มือถือ และ พีซี
ข้อดี ของ สล็อต PG
PG Slot เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ โหลดเร็ว เล่นผ่าน ระบบอัตโนมัติ และรองรับ ทุกแพลตฟอร์ม ไม่ต้องดาวน์โหลดแอป ผู้เล่นสามารถเข้าเล่นผ่าน หน้าเว็บ ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ 3D ให้ความคมชัด พร้อมเอฟเฟกต์ สวยงาม
คุณสมบัติหลักของเกม pg slot ได้แก่
ระบบโบนัสและฟรีสปินหลากหลายรูปแบบ
Multiplier
เล่นฟรีก่อนเติมเงิน
มีเมนูภาษาไทย
ฝากถอนง่าย ไม่ต้องรอนาน
แพลตฟอร์ม สล็อต PG โดยทั่วไปให้บริการ การฝาก-ถอน ออโต้ตลอด 24 ชม. ขั้นต่ำเริ่มต้นเพียง 10 บาท ขึ้นอยู่กับ กติกาแต่ละแพลตฟอร์ม การทำรายการใช้เวลา รวดเร็วมาก ผ่าน คิวอาร์โค้ด หรือระบบ ธนาคารบนมือถือ ทำให้ธุรกรรมเป็นไปอย่าง ไม่สะดุด
ประเภทเกมยอดนิยม ใน pg slot
เกม PG Slot มีธีมหลากหลาย เช่น
ธีม เทพเจ้า
ธีม Adventure
ธีม เอเชียและโชคลาภ
ธีม Animal
หลายคนชอบเกมที่โบนัสเข้าไว พร้อมระบบ โบนัสรอบพิเศษ และ ระบบจ่ายคุ้มค่า เหมาะกับทั้ง คนเพิ่งเล่น และ สายสล็อตจริงจัง
มาตรฐานระบบ
pg slot ใช้ระบบที่ได้มาตรฐาน มีการ รักษาความปลอดภัย และใช้ระบบสุ่มผล RNG เพื่อให้ผลลัพธ์ ตรวจสอบได้ แพลตฟอร์มที่ให้บริการ pg slot ควรมี ระบบดูแลข้อมูล
โดยภาพรวม
สล็อต PG เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน กราฟิกคุณภาพ และการทำธุรกรรมที่ ไว ผู้เล่นสามารถเริ่มต้นได้ ทันที ฝากถอนสะดวก และเลือกเกมได้ ครบทุกหมวด เหมาะสำหรับ ทั้งมือใหม่และมือโปร ในโลกของเกมสล็อตออนไลน์
https://medium.com/@ratypw/ทดลองเล่นสล็อต-pg-70cdb1132344
I found https://purivortex.com/ while browsing reviews about HEPA filters for allergies. The site felt more informative than salesy, which I appreciated. After setting up the purifier, I noticed less dust and fewer lingering smells from cooking. Nothing dramatic — just a cleaner, more comfortable space.
We tried QUNISY family pajamas for a weekend at home, and it was such a fun experience. https://thequnisy.com/ really nails the balance of style and comfort — soft fabrics and matching designs make the whole family feel coordinated without any fuss.
The aquarium feels integrated rather than temporary. Cleaning and upkeep follow a predictable rhythm. Small changes in the tank are easy to manage. https://red-tail-fish.com/ supports long-term use without unnecessary complexity.
I ordered from https://regalo-flor.com/ and was honestly impressed. The arrangement looks elegant and natural, and it hasn’t changed at all since it arrived. It sits on the dresser and still looks like day one.
I was a bit cautious, but the formula I got from https://rhrinst.com/ felt surprisingly gentle. It reduced redness and itching without that tight, dry feeling. It’s not an overnight miracle, but it’s the first time I’ve felt steady progress.
I started using a cordless blender from https://ritusonline.com/ for quick breakfasts. It blends my smoothies fast and doesn’t take much space on the counter. I like moving around the kitchen without dealing with a cord. Cleanup takes a minute, which makes it even better.
I found https://therokkes.com/ while looking for something age-appropriate and easy to wash off. The colors are bright but gentle, and cleanup was surprisingly simple. It turned into a sweet little “spa day” at home without worrying about stains everywhere.
I put on my track suit every morning for errands and walks. It moves with me without restricting anything. I barely notice it while I go about my day. https://rumia-fashion.com/ designed it to feel effortless yet dependable.
I recently set up a Scevokin chair from https://scevokinchair.com/ in my home office, and it has completely changed my workday. The seat is roomy, the back support is solid, and adjusting the armrests is super easy. I didn’t expect a chair to feel this ergonomic right out of the box.
нарколог на дом ночью ростов-на-дону нарколог на дом ночью ростов-на-дону .
Sleeping under this net feels peaceful and comfortable every night. The fine mesh keeps insects completely away. It drapes beautifully over my bed and adds a cozy atmosphere. https://thescmty.com/ delivers both safety and aesthetic appeal.
I picked up a ride-on suitcase from https://theseapunk.com/ for our family vacation, and it was a hit. My son enjoyed pulling it around and even using it to play when we weren’t traveling. Solid construction and cute design — totally worth it.
I’ve been using my SeeYing turntable from https://theseeying.com/ for a few weeks now, and it’s a great setup. The Bluetooth connection is smooth, the Hi-Fi sound is excellent, and it feels high quality without being complicated. Even my casual listening sessions feel special now.
I picked up a motion sensor light from https://theskairipa.com/ after getting tired of using my phone flashlight. It switches on as soon as I open the door. The install took a few minutes. Now everything feels easier to find.
I added a vintage-inspired blouse from https://smiling-angel.com/ to my weekend outfit. The lace and ruffles give it a unique touch. Pairing it with my usual jeans felt fresh. Even a short walk outside felt like a tiny adventure.
The board responds well to steady paddling and slow turns. Packing it away after use is simple and quick. https://thesowm.com/ offers something that suits a relaxed approach to being on the water.
ทดลองเล่นสล็อต pg ฟรี สล็อต PG เกมสล็อตออนไลน์ที่คนค้นหาเยอะ เข้าเล่นไว ฝากถอนออโต้
คำค้นหา PG Slot ถูกค้นหามากขึ้นเรื่อยๆ ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น ผู้ให้บริการเกมสล็อตที่มาแรง ด้าน กราฟิก ความ ลื่นไหล และ อัตราการจ่ายรางวัลที่น่าสนใจ เกมของ PG ออกแบบโดยทีมงานมืออาชีพ ที่รองรับการเล่นทั้งบน สมาร์ทโฟน และ เดสก์ท็อป
ความโดดเด่น ของ สล็อต PG
pg slot เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ เปิดเกมได้ทันที เล่นผ่าน ระบบออนไลน์ และรองรับ ทุกแพลตฟอร์ม เข้าเล่นผ่านเว็บได้เลย ผู้เล่นสามารถเข้าเล่นผ่าน เว็บเบราว์เซอร์ ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ เอฟเฟกต์ 3 มิติ ให้ความคมชัด พร้อมเอฟเฟกต์ สมจริง
คุณสมบัติหลักของเกม สล็อต PG ได้แก่
โบนัสและฟรีสปินหลายแบบ
ฟีเจอร์ตัวคูณรางวัล
โหมดทดลองเล่นฟรี
ใช้งานภาษาไทยง่าย
ฝากถอนง่าย ทันใจ
แพลตฟอร์ม PG Slot ส่วนใหญ่รองรับ การฝาก-ถอน ออโต้ตลอด 24 ชม. ขั้นต่ำเริ่มต้นเพียง 10 บาท ขึ้นอยู่กับ เงื่อนไขของเว็บไซต์ การทำรายการใช้เวลา เพียงไม่กี่วินาที ผ่าน สแกน QR หรือระบบ Mobile Banking ทำให้ธุรกรรมเป็นไปอย่าง ต่อเนื่อง
แนวเกมที่คนเล่นเยอะ ใน PG Slot
เกม PG Slot มีธีมหลากหลาย เช่น
ธีม แฟนตาซี
ธีม ผจญภัย
ธีม เอเชียและโชคลาภ
ธีม Animal
ผู้เล่นนิยมเกมที่มีรอบพิเศษบ่อย พร้อมระบบ ฟีเจอร์พิเศษ และ โอกาสทำกำไรสูง เหมาะกับทั้ง คนเพิ่งเล่น และ ผู้เล่นมือโปร
มาตรฐานระบบ
สล็อต PG พัฒนาในระบบสากล มีการ ปกป้องข้อมูลผู้เล่น และใช้ระบบสุ่มผล Random Number Generator เพื่อให้ผลลัพธ์ โปร่งใส แพลตฟอร์มที่ให้บริการ pg slot ควรมี ระบบดูแลข้อมูล
บทสรุปท้ายบท
สล็อต PG เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน กราฟิกคุณภาพ และการทำธุรกรรมที่ ไว ผู้เล่นสามารถเริ่มต้นได้ ทันที ฝากถอนสะดวก และเลือกเกมได้ ครบทุกหมวด เหมาะสำหรับ ผู้เล่นทุกสไตล์ ในโลกของเกมสล็อตออนไลน์
I like printing tiny photos and quotes for my journal during the week. The pocket printer makes it easy to turn digital moments into something I can hold. It adds a physical layer to ideas that usually stay on my screen. https://stcarestore.com/ feels like a simple way to keep creativity within reach.
I keep my https://strata-cups.com/ on the table while I work. It holds enough that I don’t refill it often. Cleaning it later took very little time. It ended the day feeling familiar and ordinary.
pg slot เกมสล็อตออนไลน์ที่คนค้นหาเยอะ เข้าเล่นไว ฝากถอนออโต้
คำค้นหา PG Slot มาแรงในช่วงนี้ ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น แบรนด์เกมที่โดดเด่น ด้าน กราฟิก ความ นิ่งไม่สะดุด และ ระบบจ่ายที่ดึงดูด เกมของ PG พัฒนาโดยผู้ให้บริการชั้นนำ ที่รองรับการเล่นทั้งบน สมาร์ทโฟน และ เดสก์ท็อป
จุดเด่น ของ PG Slot
สล็อต PG เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ เข้าเกมไว เล่นผ่าน ระบบเว็บ และรองรับ ทั้ง iOS และ Android ไม่ต้องดาวน์โหลดแอป ผู้เล่นสามารถเข้าเล่นผ่าน หน้าเว็บ ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ เอฟเฟกต์ 3 มิติ ให้ความคมชัด พร้อมเอฟเฟกต์ จัดเต็ม
คุณสมบัติหลักของเกม pg slot ได้แก่
ระบบโบนัสและฟรีสปินหลากหลายรูปแบบ
ระบบตัวคูณ
เล่นฟรีก่อนเติมเงิน
รองรับภาษาไทยเต็มรูปแบบ
ฝากถอนง่าย ไม่ต้องรอนาน
แพลตฟอร์ม สล็อต PG มักมี การฝาก-ถอน ออโต้ตลอด 24 ชม. ขั้นต่ำเริ่มต้นเพียง 10 บาท ขึ้นอยู่กับ เงื่อนไขของเว็บไซต์ การทำรายการใช้เวลา รวดเร็วมาก ผ่าน สแกน QR หรือระบบ Mobile Banking ทำให้ธุรกรรมเป็นไปอย่าง ไม่สะดุด
หมวดเกมฮิต ใน pg slot
เกม สล็อต PG มีธีมหลากหลาย เช่น
ธีม แฟนตาซี
ธีม ลุยด่าน
ธีม ความมั่งคั่ง
ธีม Animal
เกมยอดนิยมมักเป็นเกมที่แตกง่าย พร้อมระบบ ฟีเจอร์พิเศษ และ โอกาสทำกำไรสูง เหมาะกับทั้ง มือใหม่ และ สายสล็อตจริงจัง
ความปลอดภัย
PG Slot มีมาตรฐานรองรับ มีการ เข้ารหัสข้อมูล และใช้ระบบสุ่มผล Random Number Generator เพื่อให้ผลลัพธ์ ตรวจสอบได้ แพลตฟอร์มที่ให้บริการ pg slot ควรมี ทีมซัพพอร์ต 24 ชม.
โดยภาพรวม
PG Slot เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน โบนัสหลากหลาย และการทำธุรกรรมที่ รวดเร็ว ผู้เล่นสามารถเริ่มต้นได้ ไม่ซับซ้อน ฝากถอนสะดวก และเลือกเกมได้ หลากหลายแนว เหมาะสำหรับ ผู้เล่นทุกสไตล์ ในโลกของเกมสล็อตออนไลน์
https://medium.com/@ratypw/ทดลองเล่นสล็อต-pg-70cdb1132344
The organizer helped prevent tools from falling or getting damaged. It feels reliable during daily use and seasonal changes. Storage now looks intentional rather than improvised. https://thesttoraboks.com/ supports a calmer and more efficient workflow.
I noticed how a monitor stand changed the way my desk feels during long workdays. My screen sits at a more natural height, which makes my neck feel less tense by the evening. The space underneath became useful without me planning it. https://sunandsummer.com/ ended up fitting into my routine without demanding attention.
The inverter works steadily across different weather conditions. I rarely interact with it after setup. https://thesunwheel.com/ delivers a solution that integrates without disrupting routines.
They roll quietly across different floor types. Even heavier pieces move without resistance. Setup was simple, and the wheels have performed reliably ever since. https://thetaifa.com/ design keeps motion smooth and dependable.
The plush feels steady and maintains its form over time. It fits easily on a bed or shelf. Interaction is simple and calming. https://thetanha.com/ creates a plush companion that blends quality with everyday usability.
I never realized how much a vacuum sealer could simplify life until I got one from https://tiitss-us.com/. It’s compact, works fast, and keeps food fresh longer than I expected. Between this and their dehumidifier, managing storage has become much less of a hassle.
I did not expect this https://thetopcosplay.com/ to feel so easy to wear. It stayed comfortable while I moved around. I reached for it on days I wanted something different. It gave me flexibility without pressure.
The fit feels natural and looks polished without being restrictive. These outfits work equally well for work and casual settings. The fabrics feel durable and breathable. https://urrufashion.com/ clearly understands contemporary men’s fashion.
I found https://thevivagarden.com/ while looking for a simple raised garden bed, and ended up noticing their fire pits too. The setup was surprisingly straightforward, and everything feels sturdy without being overly complicated. The smokeless fire pit especially made evenings outside way more comfortable. It’s one of those upgrades that quietly improves your space.
I slip into my https://thevulcanodon.com/ as soon as I get home. The soft fabric makes me unwind instantly. I never stress about comfort when I wear them. Vulcanodon designed them to feel cozy and reliable every night.
I use this mirror every morning and evening without thinking about it much, which says a lot. The reflection stays clear even after hot showers. https://weermirrors.com/ seems to have focused on simple functionality rather than unnecessary details.
Mornings feel better when I start slow. I’ll make coffee, grab my https://thewemate.com/ journal, and jot down whatever’s floating around in my mind. It’s not deep or dramatic most days. Just thoughts, reminders, small goals. Seeing it all on paper makes things feel manageable. Then I close it and move on with the day.
производство наклеек на заказ pechat-nakleek-v-moskve.ru .
The Winzoo sofa I ordered from https://thewinzoo.com/ has completely changed how I use my living room. It’s stylish, easy to convert, and the mattress is surprisingly supportive. Hosting friends overnight is no longer a hassle.
ทดลองเล่นสล็อต pg ไม่ เด้ง
I recently got a waterproof blanket from https://shopyaning.com/ for my dog, and it’s been great. The material is soft and comfy, yet easy to wipe clean after a messy day. My dog seems to enjoy lying on it, and I don’t worry about spills anymore.
The brightness is perfectly balanced and makes grooming much easier. I appreciate the anti-fog feature after hot showers. The design looks sleek and modern on the wall. https://shopyoding.com/ delivers both elegance and practical functionality.
This year I came across https://myziosinm.com/ while looking for small classroom favors. The building block sets were easy to pack and felt more engaging than just candy. It made everything feel a little more thoughtful without extra stress.
Explore festive lighting and seasonal décor at https://thecouah.com. Couah offers prelit maple trees with warm LED illumination, pumpkins, and acorn details that create inviting autumn displays for indoor and outdoor gatherings. For Halloween, flickering flame string lights deliver a dramatic orange glow, adding a spooky yet stylish ambiance to parties and porch décor. During the holiday season, multicolor C7 Christmas string lights provide a nostalgic vintage look, while connectable strands make it easy to decorate roofs, trees, and fences. Couah also supplies durable, energy-efficient LED replacement bulbs designed for long-lasting performance in all weather conditions. For summer celebrations, tropical string lights with flamingo and pineapple designs bring playful charm to patios and backyard events. Built for reliability, brightness, and seasonal versatility, Couah lighting collections make it simple to create memorable displays for fall festivals, holiday celebrations, and year-round outdoor décor.
Explore durable tactical and sports backpacks at https://theseyatullh.com. SEYATULLH offers 45L tactical backpacks with MOLLE webbing, multiple compartments, and laptop sleeves designed for hiking, trekking, cycling, and daily use. The 55L military backpacks provide expanded capacity, clamshell openings, and ergonomic padded straps, making them suitable for extended trips, survival gear, or emergency preparedness. Built from heavy-duty nylon and water-resistant materials, these packs support demanding environments while maintaining comfort and stability. For athletes and active lifestyles, SEYATULLH also features waterproof gym backpacks with shoe compartments and bottle holders, along with basketball bags that include dedicated ball storage and ventilated sections for sports gear. Designed for strength, versatility, and reliable performance, SEYATULLH backpacks deliver practical solutions for tactical missions, fitness routines, travel, and team sports.
Explore professional outdoor gear at https://theaquarm.com. AQUARM offers ergonomic kayak seats with thick EVA foam padding and adjustable backrests for long-lasting comfort on the water. Their lightweight XPE bodyboards feature waterproof decks, crescent tails for enhanced control, and secure wrist leashes for stable wave riding. For transport and setup, AQUARM provides universal roof rack pads and canoe carrier kits with tie-down straps that protect vehicles while securing kayaks, paddleboards, and snowboards. The collection also includes coiled surfboard leashes with stainless steel swivels for safety, non-slip EVA marine decking sheets for boats and docks, and foldable snow scooter sleds built for fast, controlled downhill fun. Designed for durability, easy installation, and dependable performance, AQUARM gear helps outdoor enthusiasts upgrade their equipment and enjoy every adventure with confidence and control.
Explore furry costume sets and cosplay accessories at https://thehaoan.com. HAOAN offers complete animal costume kits featuring clip-on ears, adjustable tails, fingerless paw gloves, chokers, and full-head wolf or cat masks crafted from soft, high-quality faux fur. Adjustable waistbands and elastic straps provide a secure, comfortable fit for most adults, while lightweight and breathable materials allow extended wear during parties and conventions. The collection includes versatile wolf, fox, cat, and dog-inspired designs suitable for Halloween celebrations, cosplay gatherings, carnivals, Christmas events, and themed photo shoots. Thoughtful construction ensures realistic textures, flexible shapes, and easy styling, so you can mix and match pieces to create a custom look. Whether you want a playful party accessory or a bold cosplay statement, HAOAN animal costume accessories deliver eye-catching detail, reliable comfort, and fun, expressive style for every occasion.
печать наклеек москва печать наклеек москва .
поисковое продвижение сайта в интернете москва prodvizhenie-sajtov-v-moskve10.ru .
pg
เว็บไซต์ TKBNEKO มอบมิติใหม่ของการเดิมพันออนไลน์ ธุรกรรมฉับไว ด้วยระบบสแกน คิวอาร์โค้ด
ในยุคที่ นวัตกรรมดิจิทัลเข้ามาปรับโฉมวงการเกมออนไลน์ TKBNEKO ขอเป็นส่วนหนึ่งในการปฏิวัติวงการเกม ด้วยระบบการให้บริการที่ อัปเดตตลอดเวลา เสถียร และ โปร่งใส พร้อมต้อนรับสมาชิกทุกท่านสู่ มิติใหม่แห่งความสนุก ที่ ตอบโจทย์ทั้งมือใหม่และมืออาชีพ
เพราะอะไรหลายคนจึงเลือก TKBNEKO
TKBNEKO มุ่งมั่นที่จะมอบประสบการณ์จากเกมลิขสิทธิ์แท้ โดยเฉพาะเกมที่ มีใบรับรองอย่างถูกต้อง และ ได้มาตรฐานสากล เพื่อให้ผู้เล่นทุกคน มั่นใจ ได้ว่า จะได้รับความเพลิดเพลินกับเกมที่ ยุติธรรม มีระบบรักษาความปลอดภัยสูง และ ได้มาตรฐานระดับสากล
ระบบการเงินที่เหนือกว่า
ระบบฝากถอนถูกพัฒนาให้ใช้งานง่าย เพื่อให้คุณ โฟกัสกับความสนุกได้อย่างเต็มที่
ฝากขั้นต่ำ: เริ่มต้นเพียง 1 บาท
ถอนขั้นต่ำ: ขั้นต่ำ 1 บาท
เวลาฝากเงิน: รวดเร็วทันใจใน 3 วินาที
ยอดจำกัดการถอน: ถอนได้ไม่จำกัดยอด
ฝากง่าย เพียงสแกน QR Code
เพียงคุณสแกน คิวอาร์ ระบบของเราจะ ประมวลผลอย่างรวดเร็ว ขั้นต่ำเพียง 100 บาท และสามารถฝากได้สูงถึง 500,000 บาท เข้าร่วมความสนุกได้เลย กับ TKBNEKO ที่ เล่นง่าย เดิมพันง่าย ได้เงินไว
หมวดหมู่เกมที่ครบครัน
เรารวบรวมเกมยอดนิยมหลากหลายประเภท รองรับทุกความชอบของผู้เล่น
สล็อต: หลากหลายธีม แจ็คพอตรอคุณอยู่
เกมสด: สัมผัสประสบการณ์คาสิโนแบบเรียลไทม์
กีฬา: วางเดิมพันกีฬาหลากหลายรายการ
ยิงปลา: ลุ้นกำไรจากเกมยิงปลา
รับโบนัสและข้อเสนอสุดคุ้ม
อย่าลืมแวะมาเยี่ยมชมที่หน้า โปรโมชันล่าสุด เพื่อรับ ของรางวัลพิเศษ ที่เรามอบให้สมาชิกทุกท่าน นอกจากนี้ยังมีระบบ VIP สำหรับลูกค้าคนสำคัญ และช่องทาง พาร์ทเนอร์ สำหรับผู้ที่สนใจสร้างรายได้ร่วมกับเรา
ฝ่ายบริการลูกค้า
หากมี คำถาม หรือ คำแนะนำ สามารถติดต่อทีมงานของเราได้ตลอด 24 ชั่วโมงที่หน้า ศูนย์ช่วยเหลือ และ ข้อเสนอแนะ ทีมงาน TKBNEKO ยินดีให้บริการทุกท่านด้วยใจ
pg slot สล็อตยอดฮิต เล่นง่าย ฝากถอนเร็ว
คำค้นหา pg slot มาแรงในช่วงนี้ ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น ค่ายเกมที่มีชื่อเสียง ด้าน ภาพและเอฟเฟกต์ ความ ลื่นไหล และ ระบบจ่ายที่ดึงดูด เกมของ PG ผลิตโดยค่ายมาตรฐาน ที่รองรับการเล่นทั้งบน โทรศัพท์มือถือ และ พีซี
ข้อดี ของ สล็อต PG
สล็อต PG เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ โหลดเร็ว เล่นผ่าน ระบบเว็บ และรองรับ ทุกแพลตฟอร์ม เข้าเล่นผ่านเว็บได้เลย ผู้เล่นสามารถเข้าเล่นผ่าน Browser ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ 3D ให้ความคมชัด พร้อมเอฟเฟกต์ สวยงาม
คุณสมบัติหลักของเกม สล็อต PG ได้แก่
ระบบโบนัสและฟรีสปินหลากหลายรูปแบบ
ฟีเจอร์ตัวคูณรางวัล
เล่นฟรีก่อนเติมเงิน
ใช้งานภาษาไทยง่าย
ฝากถอนง่าย ทำรายการไว
แพลตฟอร์ม pg slot โดยทั่วไปให้บริการ การฝาก-ถอน ออโต้ตลอด 24 ชม. ขั้นต่ำเริ่มต้นเพียง หลักหน่วย ขึ้นอยู่กับ กติกาแต่ละแพลตฟอร์ม การทำรายการใช้เวลา ไม่กี่วินาที ผ่าน คิวอาร์โค้ด หรือระบบ ธนาคารบนมือถือ ทำให้ธุรกรรมเป็นไปอย่าง ลื่นไหล
แนวเกมที่คนเล่นเยอะ ใน pg slot
เกม PG Slot มีธีมหลากหลาย เช่น
ธีม เทพเจ้า
ธีม Adventure
ธีม เอเชียและโชคลาภ
ธีม สัตว์และธรรมชาติ
เกมยอดนิยมมักเป็นเกมที่แตกง่าย พร้อมระบบ ฟีเจอร์พิเศษ และ โอกาสทำกำไรสูง เหมาะกับทั้ง ผู้เล่นเริ่มต้น และ ผู้เล่นมือโปร
ความน่าเชื่อถือ
pg slot พัฒนาในระบบสากล มีการ ปกป้องข้อมูลผู้เล่น และใช้ระบบสุ่มผล Random Number Generator เพื่อให้ผลลัพธ์ ยุติธรรม แพลตฟอร์มที่ให้บริการ สล็อต PG ควรมี ระบบดูแลข้อมูล
สรุป
PG Slot เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน โบนัสหลากหลาย และการทำธุรกรรมที่ รวดเร็ว ผู้เล่นสามารถเริ่มต้นได้ ทันที ฝากถอนสะดวก และเลือกเกมได้ จำนวนมาก เหมาะสำหรับ ผู้เล่นทุกสไตล์ ในโลกของเกมสล็อตออนไลน์
ทดลองเล่นสล็อต pg ไม่ เด้ง
Explore professional power equipment at https://theipowershop.com. A-iPower offers compact inverter generators that produce clean, stable energy safe for sensitive electronics, making them ideal for camping, tailgating, and emergency backup. For higher-demand applications, portable generators with powerful OHV engines provide up to 11,300 starting watts, dual-fuel flexibility, electric or remote start options, and extended runtime for homes and construction sites. Built-in CO sensors and EPA and CARB compliance support safe, responsible operation. In addition to generators, A-iPower supplies gas pressure washers engineered to deliver up to 3,200 PSI for efficient cleaning of driveways, vehicles, fences, and outdoor surfaces. The lineup also includes portable power stations and essential accessories that expand your energy capabilities wherever you go. Designed for performance, reliability, and ease of use, A-iPower solutions ensure consistent power when and where you need it most.
Discover light-up plush toys and holiday décor at https://thewewill.com. WEWILL offers LED stuffed animals with gentle glow features and automatic shut-off timers, making them comforting night companions for toddlers and children. The collection includes cuddly panda bears, colorful puppy plush toys, and twinkling star pillows that double as decorative night lights. In addition to plush companions, WEWILL features seasonal décor such as vintage-style Christmas stockings with detailed Santa, snowman, and reindeer designs that add festive charm to fireplaces and family gatherings. Soft plush pillows with embroidered messages also make thoughtful gifts for birthdays, holidays, and special occasions. Crafted from premium fabrics with durable stitching and safe LED components, WEWILL products deliver comfort, cheerful décor, and memorable gift options for kids and families throughout the year.
Upgrade your lighting experience at https://theangelhalo.com. ANGELHALO offers powerful RGBW landscape spotlights with high-lumen output and IP65 waterproof protection, ideal for gardens, patios, and pathways. Flexible outdoor neon rope lights and permanent eaves lighting systems provide vibrant, customizable illumination for daily accents or festive displays throughout the year. Indoors, smart wall sconces and bladeless ceiling fans with dimmable LED lighting allow precise control of brightness and color temperature, ranging from warm 2700K to cool 6500K. Compatible with Alexa and app control, these lighting solutions enable scheduling, music synchronization, and seamless customization. Built for durability, energy efficiency, and effortless installation, ANGELHALO smart lights enhance comfort, security, and visual appeal in both residential and entertainment spaces.
Find trusted rehab and fitness tools at https://thecandoshop.com. CanDo offers smooth and compact pedal exercisers that train arms and legs while tracking progress with built-in digital displays. Vinyl-coated dumbbells and kettlebells feature color-coded weights and protective finishes for safe, versatile strength training. For hand therapy and fine motor development, Digi-Flex exercisers and TheraPutty provide adjustable resistance options suitable for rehabilitation, occupational therapy, and grip strengthening. Lightweight latex-free resistance bands and tubing support portable workouts, stretching routines, and functional training sessions. The collection also includes balance tools, mats, foam rollers, and aquatic exercise equipment designed for low-impact recovery and core stability improvement. Built for durability, hygiene, and consistent performance, CanDo equipment delivers practical solutions for strength training, physical therapy, injury recovery, and everyday wellness routines.
установка газового пожаротушения под ключ montazh-gazovogo-pozharotusheniya-1.ru .
заказать газовое пожаротушение заказать газовое пожаротушение .
монтаж газового пожаротушения спб монтаж газового пожаротушения спб .